
简介
Spark课程实验案例:Spark+Kafka构建实时分析Dashboard
环境准备
软件版本
- Vmware: 16.2.1
- Ubuntu: 16.04
- Hadoop: 2.7.1
- Spark: 2.1.0
- Scala: 2.11.8
- kafka: 0.8.2.2, 0.10.2.0
- python: 3.6
安装教程
系统环境
# 更新源 http://mirrors.aliyun.com/ubuntu/
sudo apt-get update
sudo apt-get install vim
sudo apt-get install openssh-server
# 添加用户
sudo useradd -m hadoop -s /bin/bash
sudo passwd hadoop
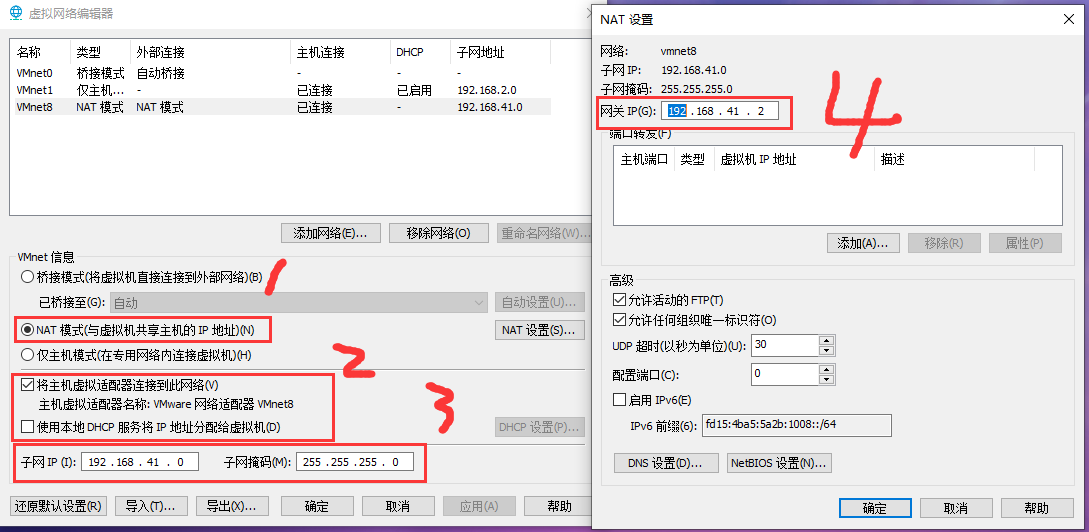
配置固定ip: vim /etc/network/interfaces
auto lo
iface lo inet loopback
auto ens33
iface ens33 inet static
address 192.168.41.129
netmask 255.255.255.0
gateway 192.168.41.2
dns-nameservers 8.8.8.8 114.114.114.114
重启生效:
sudo /etc/init.d/networking restart
ifconfig
环境变量:vi /etc/profile
export JAVA_HOME=/usr/local/java
export SCALA_HOME=/usr/local/scala
export MAVEN_HOME=/usr/local/maven
export GRADLE_HOME=/usr/local/gradle
export CLASSPATH=.:${JAVA_HOME}/lib
export PATH=${JAVA_HOME}/bin:$PATH:$MAVEN_HOME/bin:$SCALA_HOME/bin:$GRADLE_HOME/bin
Hadoop
# 免密钥
ssh-keygen -t rsa
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
chmod 600 ~/.ssh/authorized_keys
ssh localhost pwd
# 开始安装
tar -zxvf hadoop-2.7.1.tar.gz -C /usr/local/
cd /usr/local/
ln -snf hadoop-2.7.1 hadoop
chown -R hadoop:hadoop hadoop*
修改环境变量:vi ~/.bashrc
export HADOOP_HOME=/usr/local/hadoop
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export SPARK_HOME=/usr/local/spark
export KAFKA_HOME=/usr/local/kafka
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$SPARK_HOME/bin:$KAFKA_HOME/bin
修改配置文件
vi /usr/local/hadoop/etc/hadoop/core-site.xml
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/usr/local/hadoop/tmp</value>
<description>Abase for other temporary directories.</description>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>
vi /usr/local/hadoop/etc/hadoop/hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/local/hadoop/tmp/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/local/hadoop/tmp/dfs/data</value>
</property>
</configuration>
启动:
hadoop namenode -format
start-dfs.sh
# 测试
hdfs dfs -mkdir -p /user/hadoop/input
hdfs dfs -put ${HADOOP_HOME}/etc/hadoop/*.xml /user/hadoop/input
hadoop jar ${HADOOP_HOME}/share/hadoop/mapreduce/hadoop-mapreduce-examples-*.jar grep input output 'dfs[a-z.]+'
hdfs dfs -cat /user/hadoop/output/*
Kafka
# 开始安装
tar -zxvf kafka_2.11-0.10.2.0.tgz -C /usr/local/
cd /usr/local/
ln -snf kafka_2.11-0.10.2.0 kafka
chown -R hadoop:hadoop kafka*
cd /usr/local/kafka
# 启动zookeeper
nohup bin/zookeeper-server-start.sh config/zookeeper.properties 2>&1 > logs/zookeeper.out &
# 启动kafka
nohup bin/kafka-server-start.sh config/server.properties 2>&1 > logs/kafka.out &
常用操作
# 创建主题
kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic dblab
# 列出所有主题
kafka-topics.sh --list --zookeeper localhost:2181
# 控制台生产者
kafka-console-producer.sh --broker-list localhost:9092 --topic dblab
# 控制台消费者
kafka-console-consumer.sh --zookeeper localhost:2181 --topic dblab --from-beginning
Spark
# 开始安装
tar -zxvf spark-2.1.0-bin-without-hadoop.tgz -C /usr/local/
cd /usr/local/
ln -snf spark-2.1.0-bin-without-hadoop spark
chown -R hadoop:hadoop spark*
# 依赖kafka时需要把相应的包移动到jars下面
cp spark-streaming-kafka-0-8_2.11-2.1.0.jar /usr/local/spark/jars/
修改启动脚本:vi /usr/local/spark/conf/spark-env.sh
export SPARK_DIST_CLASSPATH=$(/usr/local/hadoop/bin/hadoop classpath):/usr/local/spark/jars/kafka/*:/usr/local/kafka/libs/*
# 指定使用的python
export PYSPARK_PYTHON=/usr/bin/python3
Python
# 安装编译依赖
apt-get install zlib*
apt-get install openssl
apt-get install libssl-dev
# 下载并编译
wget http://npm.taobao.org/mirrors/python/3.6.14/Python-3.6.14.tgz
tar -zxvf Python-3.6.14.tgz
cd Python-3.6.14
# 编译添加 ssl 模块
./configure --prefix=/usr/local/python-3.6.14 --with-ssl
# 解决 ubuntu 下缺少 lsb_release 模块报错
cp -f /usr/lib/python3/dist-packages/lsb_release.py /usr/local/python-3.6.14/lib/python3.6/
make && make install
# 创建软链
cd /usr/local && ln -snf python-3.6.14/ python3.6
# ubuntu下面进入 /usr/bin 修改系统默认软链
cd /usr/bin/
ln -snf /usr/local/python3.6/bin/python3 python3
ln -snf /usr/local/python3.6/bin/python3-config python3-config
ln -snf /usr/local/python3.6/bin/pip3 pip3
python3 --version && pip3 --version

python依赖
# 豆瓣源 -i http://pypi.douban.com/simple/ --trusted-host=pypi.douban.com
pip3 install Flask==2.0.3
pip3 install flask-socketio==4.3.1
pip3 install python-engineio==3.13.2
pip3 install python-socketio==4.6.0
pip3 install kafka-python==2.0.2
启动应用
流处理
源码:
工具类:StreamingExamples.scala
package org.apache.spark.examples.streaming
import org.apache.spark.internal.Logging
import org.apache.log4j.{Level, Logger}
/** Utility functions for Spark Streaming examples. */
object StreamingExamples extends Logging {
/** Set reasonable logging levels for streaming if the user has not configured log4j. */
def setStreamingLogLevels() {
val log4jInitialized = Logger.getRootLogger.getAllAppenders.hasMoreElements
if (!log4jInitialized) {
// We first log something to initialize Spark's default logging, then we override the
// logging level.
logInfo("Setting log level to [WARN] for streaming example." +
" To override add a custom log4j.properties to the classpath.")
Logger.getRootLogger.setLevel(Level.WARN)
}
}
}
处理类:KafkaWordCount.scala
package org.apache.spark.examples.streaming
import org.apache.kafka.clients.producer.{KafkaProducer, ProducerConfig, ProducerRecord}
import org.apache.spark.SparkConf
import org.apache.spark.streaming._
import org.apache.spark.streaming.kafka._
import org.json4s._
import org.json4s.jackson.Serialization.write
import java.util.HashMap
object KafkaWordCount {
implicit val formats = DefaultFormats
def main(args: Array[String]): Unit = {
if (args.length < 4) {
System.err.println("Usage: KafkaWordCount <zkQuorum> <group> <topics> <numThreads>")
System.exit(1)
}
StreamingExamples.setStreamingLogLevels()
val Array(zkQuorum, group, topics, numThreads) = args
val sparkConf = new SparkConf().setAppName("KafkaWordCount")
val ssc = new StreamingContext(sparkConf, Seconds(1))
ssc.checkpoint(".")
val topicMap = topics.split(",").map((_, numThreads.toInt)).toMap
val lines = KafkaUtils.createStream(ssc, zkQuorum, group, topicMap).map(_._2)
val words = lines.flatMap(_.split(" "))
val wordCounts = words.map(x => (x, 1L))
.reduceByKeyAndWindow(_ + _, _ - _, Seconds(1), Seconds(1), 1).foreachRDD(rdd => {
if (rdd.count != 0) {
val props = new HashMap[String, Object]()
props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "127.0.0.1:9092")
props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,
"org.apache.kafka.common.serialization.StringSerializer")
props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG,
"org.apache.kafka.common.serialization.StringSerializer")
val producer = new KafkaProducer[String, String](props)
val str = write(rdd.collect)
val message = new ProducerRecord[String, String]("result", null, str)
producer.send(message)
}
})
ssc.start()
ssc.awaitTermination()
}
}
依赖文件pom.xml
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>org.apache.spark.examples.streaming</groupId>
<artifactId>simple-project_2.11</artifactId>
<version>1.0</version>
<packaging>jar</packaging>
<name>simple-project_2.11</name>
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<project.reporting.outputEncoding>UTF-8</project.reporting.outputEncoding>
<maven.compiler.encoding>UTF-8</maven.compiler.encoding>
<maven.compiler.source>1.8</maven.compiler.source>
<maven.compiler.target>1.8</maven.compiler.target>
</properties>
<dependencies>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.11</artifactId>
<version>2.1.0</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming_2.11</artifactId>
<version>2.1.0</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming-kafka-0-8_2.11</artifactId>
<version>2.1.0</version>
</dependency>
<dependency>
<groupId>org.json4s</groupId>
<artifactId>json4s-jackson_2.11</artifactId>
<version>3.2.11</version>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>net.alchim31.maven</groupId>
<artifactId>scala-maven-plugin</artifactId>
<version>3.2.2</version>
<executions>
<execution>
<goals>
<goal>compile</goal>
<goal>testCompile</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>
<repositories>
<repository>
<id>public</id>
<name>aliyun nexus</name>
<url>https://maven.aliyun.com/repository/public</url>
<releases>
<enabled>true</enabled>
</releases>
</repository>
</repositories>
<pluginRepositories>
<pluginRepository>
<id>public</id>
<name>aliyun nexus</name>
<url>https://maven.aliyun.com/repository/public</url>
<releases>
<enabled>true</enabled>
</releases>
<snapshots>
<enabled>false</enabled>
</snapshots>
</pluginRepository>
</pluginRepositories>
</project>
启动实时流处理:
# 编译并启动
cd /usr/local/spark/mycode/kafkatest1
mvn clean install -DskipTests
/usr/local/spark/bin/spark-submit \
--driver-class-path /usr/local/spark/jars/*:/usr/local/spark/jars/kafka/* \
--class "org.apache.spark.examples.streaming.KafkaWordCount" \
/usr/local/spark/mycode/kafkatest1/target/simple-project_2.11-1.0.jar 127.0.0.1:2181 1 sex 1
生产者
cd /usr/local/spark/mycode/labproject/scripts
python3 producer.py
源码:
# coding: utf-8
import csv
import time
from kafka import KafkaProducer
producer = KafkaProducer(bootstrap_servers='192.168.41.129:9092')
csvfile = open("../data/user_log.csv", "r", encoding='utf-8')
reader = csv.reader(csvfile)
for line in reader:
gender = line[9]
if gender == 'gender':
continue
print(line[9])
producer.send('sex', line[9].encode('utf8'))
消费者
cd /usr/local/spark/mycode/labproject/scripts
python3 consumer.py
源码:
from kafka import KafkaConsumer
consumer = KafkaConsumer('result', auto_offset_reset='earliest', bootstrap_servers='192.168.41.129:9092')
for msg in consumer:
print((msg.value).decode('utf8'))
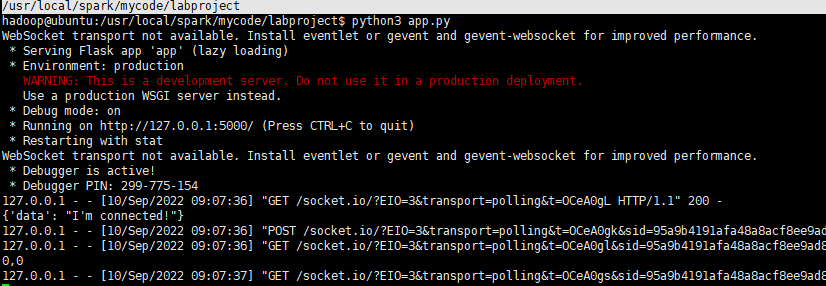
启动系统
# 启动spark-streaming程序
cd /usr/local/spark/mycode/kafkatest1
sh startup.sh
# 启动消费者
cd /usr/local/spark/mycode/labproject/scripts
python3 consumer.py
# 启动 flask 页面
cd /usr/local/spark/mycode/labproject
python3 app.py
# 启动生产者
cd /usr/local/spark/mycode/labproject/scripts
python3 producer.py
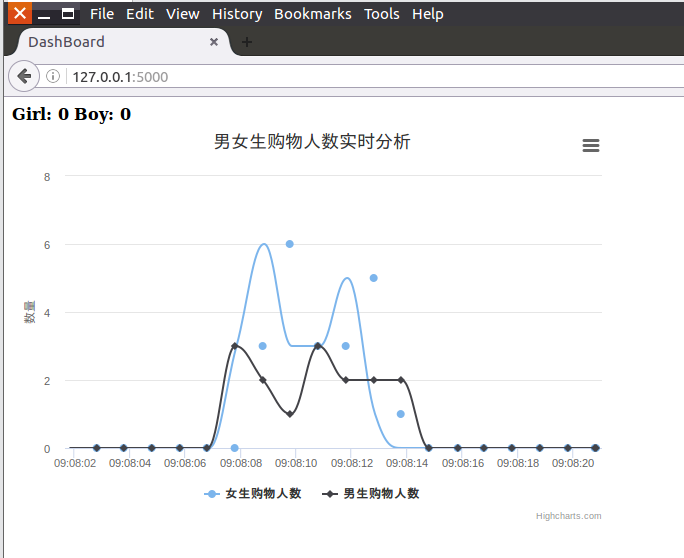
访问页面:http://127.0.0.1:5000
代码结构:
入口:app.py
import json
from flask import Flask, render_template
from flask_socketio import SocketIO
from kafka import KafkaConsumer
app = Flask(__name__)
app.config['SECRET_KEY'] = 'secret!'
socketio = SocketIO(app)
thread = None
consumer = KafkaConsumer('result', bootstrap_servers='192.168.41.129:9092')
def background_thread():
girl = 0
boy = 0
for msg in consumer:
data_json = msg.value.decode('utf8')
data_list = json.loads(data_json)
for data in data_list:
if '0' in data.keys():
girl = data['0']
elif '1' in data.keys():
boy = data['1']
else:
continue
result = str(girl) + ',' + str(boy)
print(result)
socketio.emit('test_message', {'data': result})
@socketio.on('test_connect')
def connect(message):
print(message)
global thread
if thread is None:
thread = socketio.start_background_task(target=background_thread)
socketio.emit('connected', {'data': 'Connected'})
@app.route("/")
def handle_mes():
return render_template("index.html")
if __name__ == '__main__':
socketio.run(app, debug=True)