
批处理任务
依赖
<properties>
<maven.compiler.source>8</maven.compiler.source>
<maven.compiler.target>8</maven.compiler.target>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<project.reporting.outputEncoding>UTF-8</project.reporting.outputEncoding>
<flink.version>1.12.3</flink.version>
<scala.binary.version>2.11</scala.binary.version>
</properties>
<dependencies>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-java</artifactId>
<version>${flink.version}</version>
</dependency>
<!-- java stream -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
</dependency>
<!-- scala stream -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-scala_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-clients_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-yarn_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>log4j</groupId>
<artifactId>log4j</artifactId>
<version>1.2.17</version>
</dependency>
</dependencies>
代码
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.java.DataSet;
import org.apache.flink.api.java.ExecutionEnvironment;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.util.Collector;
public class WordCountBatchByJava {
public static void main(String[] args) throws Exception {
// 创建执行环境
ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
// 加载或创建源数据
DataSet<String> text = env.fromElements("this a book", "i love china", "i am chinese");
// 转化处理数据
DataSet<Tuple2<String, Integer>> ds = text.flatMap(new LineSplitter()).groupBy(0).sum(1);
// 输出数据到目的端
ds.print();
// 执行任务操作
// 由于是Batch操作,当DataSet调用print方法时,源码内部已经调用Excute方法,所以此处不再调用,如果调用会出现错误
//env.execute("Flink Batch Word Count By Java");
}
static class LineSplitter implements FlatMapFunction<String, Tuple2<String, Integer>> {
@Override
public void flatMap(String line, Collector<Tuple2<String, Integer>> collector) {
for (String word : line.split(" ")) {
collector.collect(new Tuple2<>(word, 1));
}
}
}
}
编译
rm -r -f *.class
javac -cp .:lib/* *.java
echo -e "Manifest-Version: 1.0\nMain-Class: WordCountBatchByJava" > MANIFEST.MF
jar -cvfm example.jar MANIFEST.MF *.class
运行
- 注意不能设置
-d或者--detached run -t支持remote,local,kubernetes-session,yarn-per-job,yarn-sessionrun-application -t支持kubernetes-application,yarn-application
| 模式 | 实现类 |
|---|---|
| yarn-per-job | org.apache.flink.yarn.executors.YarnJobClusterExecutorFactory |
| yarn-session | org.apache.flink.yarn.executors.YarnSessionClusterExecutor |
| local | org.apache.flink.client.deployment.executors.LocalExecutorFactory |
/home/dubbo/flink-streaming-platform-agent/flink/bin/flink \
run -t yarn-per-job \
-Djobmanager.memory.process.size=1024mb \
-Dtaskmanager.memory.process.size=1024mb \
-Dtaskmanager.numberOfTaskSlots=1 \
-Dparallelism.default=1 \
-Dyarn.application.name=youhl_test_01 \
-c WordCountBatchByJava \
example.jar
运行结果:
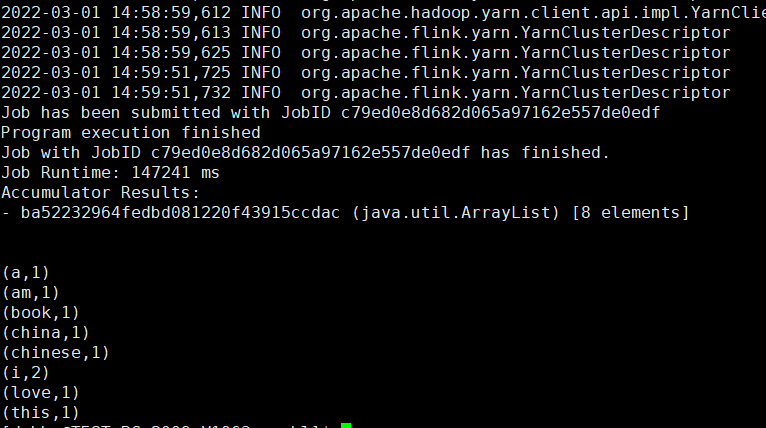
如果用
detached模式提交,作业不能以collect,printToErr,count等operator做结尾,当作业以blocking模式提交的时候就没有这些限制。
流处理任务
代码
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.common.typeinfo.TypeInformation;
import org.apache.flink.api.java.tuple.Tuple;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.KeyedStream;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.datastream.WindowedStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.windowing.assigners.TumblingProcessingTimeWindows;
import org.apache.flink.streaming.api.windowing.time.Time;
import org.apache.flink.streaming.api.windowing.windows.TimeWindow;
public class WordCountStreamingByJava {
public static void main(String[] args) throws Exception {
// 创建执行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
String host = args[0];
int port = Integer.parseInt(args[1]);
System.out.println("Connect to " + host + ":" + port);
DataStreamSource<String> source = env.socketTextStream(host, port, "\n");
// 转化处理数据
SingleOutputStreamOperator<WordWithCount> s1 = source.flatMap(
(FlatMapFunction<String, WordWithCount>) (line, collector) -> {
for (String word : line.split("\\s+")) {
collector.collect(new WordWithCount(word, 1));
}
}).returns(TypeInformation.of(WordWithCount.class));
KeyedStream<WordWithCount, Tuple> s2 = s1.keyBy("word");
// 设置窗口函数
WindowedStream<WordWithCount, Tuple, TimeWindow> s3 = s2.window(
TumblingProcessingTimeWindows.of(Time.seconds(2)));
// 计算时间窗口内的词语个数
DataStream<WordWithCount> s4 = s3.sum("count");
// 输出数据到目的端
s4.print();
// 执行任务操作
env.execute("Flink Streaming Word Count By Java");
}
public static class WordWithCount {
public String word;
public int count;
public WordWithCount() {
}
public WordWithCount(String word, int count) {
this.word = word;
this.count = count;
}
@Override
public String toString() {
return "WordWithCount{" +
"word='" + word + '\'' +
", count=" + count +
'}';
}
}
}
运行
# 在targetIp上启动端口,模拟数据流入
nc -l 9999
# 启动流处理任务
/home/dubbo/flink-streaming-platform-agent/flink/bin/flink \
run -t yarn-per-job \
-Djobmanager.memory.process.size=1024mb \
-Dtaskmanager.memory.process.size=1024mb \
-Dtaskmanager.numberOfTaskSlots=1 \
-Dparallelism.default=1 \
-Dyarn.application.name=youhl_test_02 \
-c WordCountStreamingByJava \
example.jar ${targetIp} 9999
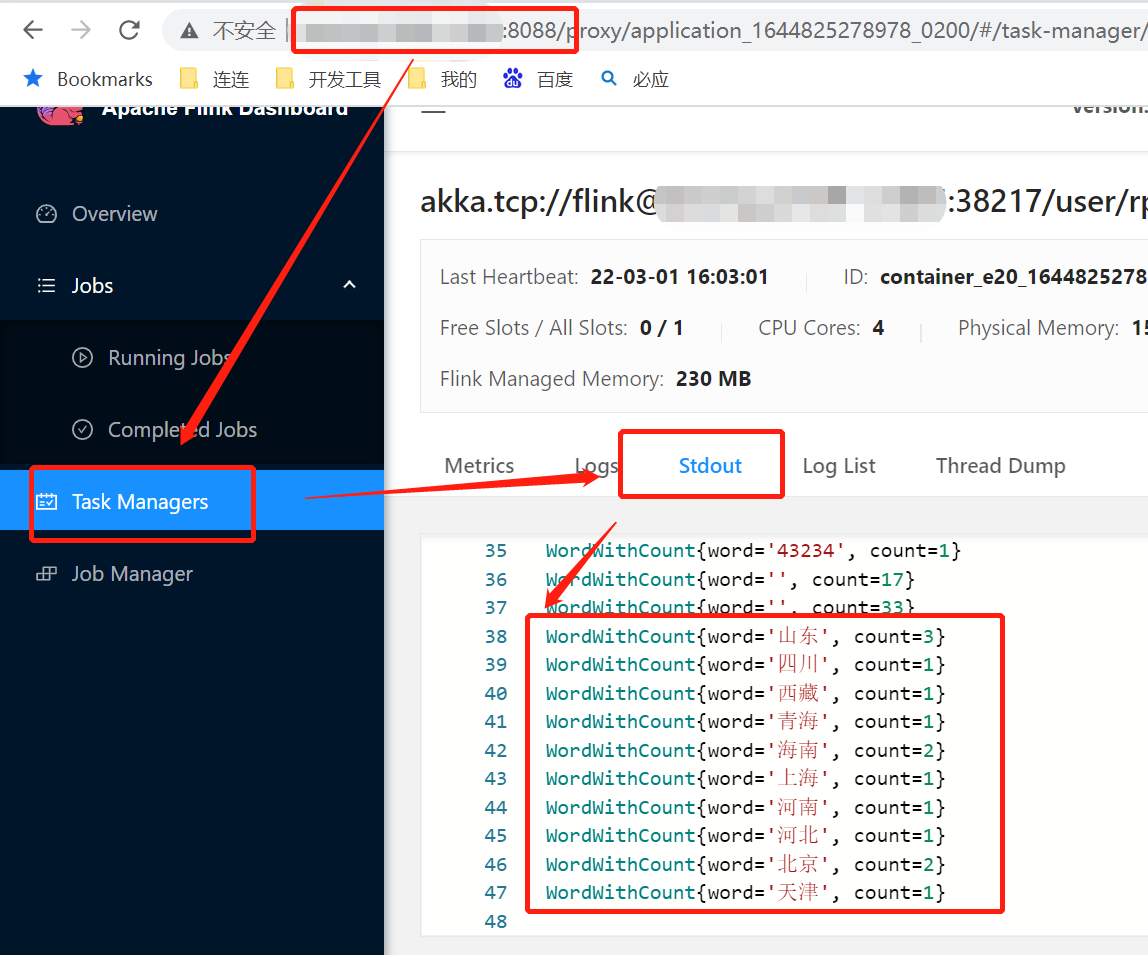
输入数据流:
山东 天津 北京 河北 河南 山东 上海 北京
山东 海南 青海 西藏 四川 海南
流式计算结果:
官方代码
SocketWindowWordCountByJava
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.common.functions.ReduceFunction;
import org.apache.flink.api.java.utils.ParameterTool;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.windowing.assigners.TumblingProcessingTimeWindows;
import org.apache.flink.streaming.api.windowing.time.Time;
import org.apache.flink.util.Collector;
public class SocketWindowWordCountByJava {
public static void main(String[] args) throws Exception {
// 获取命令传递参数 --host xx.xx.xx.xx --port 9999
ParameterTool params = ParameterTool.fromArgs(args);
String host = params.get("host");
int port = params.getInt("port");
System.out.println("Connect to " + host + ":" + port);
// 构建流环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 接入socket数据
DataStream<String> text = env.socketTextStream(host, port, "\n");
DataStream<WordWithCount> windowCounts =
text.flatMap(new InnerMapper())
.keyBy(value -> value.word)
.window(TumblingProcessingTimeWindows.of(Time.seconds(5)))
.reduce(new InnerReducer());
windowCounts.print();
env.execute("Socket Window WordCount");
}
private static class InnerMapper implements FlatMapFunction<String, WordWithCount> {
@Override
public void flatMap(String value, Collector<WordWithCount> out) throws Exception {
for (String word : value.split("\\s")) {
out.collect(new WordWithCount(word, 1L));
}
}
}
private static class InnerReducer implements ReduceFunction<WordWithCount> {
@Override
public WordWithCount reduce(WordWithCount a, WordWithCount b) throws Exception {
return new WordWithCount(a.word, a.count + b.count);
}
}
private static class WordWithCount {
public String word;
public long count;
public WordWithCount() {
}
public WordWithCount(String word, long count) {
this.word = word;
this.count = count;
}
@Override
public String toString() {
return word + " : " + count;
}
}
}
SocketWindowWordCountByScala
import org.apache.flink.api.java.utils.ParameterTool
import org.apache.flink.streaming.api.scala._
import org.apache.flink.streaming.api.windowing.assigners.TumblingProcessingTimeWindows
import org.apache.flink.streaming.api.windowing.time.Time
object SocketWindowWordCountByScala {
def main(args: Array[String]): Unit = {
val pt = ParameterTool.fromArgs(args)
val host = pt.get("host")
val port = pt.getInt("port")
println("Connect to " + host + ":" + port);
val env: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
val text: DataStream[String] = env.socketTextStream(host, port, '\n')
val windowCounts = text
.flatMap { w => w.split("\\s") }
.map { w => (w, 1) }
.keyBy(_._1)
.window(TumblingProcessingTimeWindows.of(Time.seconds(5)))
.reduce((a, b) => (a._1, a._2 + b._2))
windowCounts.print().setParallelism(1)
env.execute("Socket Window WordCount")
}
}