有界数据流
依赖
<properties>
<maven.compiler.source>8</maven.compiler.source>
<maven.compiler.target>8</maven.compiler.target>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<project.reporting.outputEncoding>UTF-8</project.reporting.outputEncoding>
<flink.version>1.12.3</flink.version>
<scala.binary.version>2.11</scala.binary.version>
<hive.version>3.1.0</hive.version>
<hadoop.version>3.1.1</hadoop.version>
</properties>
<dependencies>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-java</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-common</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-clients_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
</dependency>
<!-- scala stream -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-scala_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-planner-blink_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
</dependency>
<!-- connect hive -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-hive_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-hbase-1.4_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
</dependency>
<!-- Hive Dependency -->
<dependency>
<groupId>org.apache.hive</groupId>
<artifactId>hive-exec</artifactId>
<version>${hive.version}</version>
<exclusions>
<exclusion>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId>
</exclusion>
<exclusion>
<groupId>org.eclipse.jetty</groupId>
<artifactId>*</artifactId>
</exclusion>
<exclusion>
<artifactId>calcite-druid</artifactId>
<groupId>org.apache.calcite</groupId>
</exclusion>
<exclusion>
<artifactId>calcite-core</artifactId>
<groupId>org.apache.calcite</groupId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>${hadoop.version}</version>
<exclusions>
<exclusion>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId>
</exclusion>
<exclusion>
<groupId>org.eclipse.jetty</groupId>
<artifactId>*</artifactId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>log4j</groupId>
<artifactId>log4j</artifactId>
<version>1.2.17</version>
</dependency>
</dependencies>
代码
import org.apache.flink.api.scala._
import org.apache.flink.streaming.api.scala.StreamExecutionEnvironment
import org.apache.flink.table.api.bridge.scala.{StreamTableEnvironment, _}
import org.apache.flink.table.api.{EnvironmentSettings, _}
import org.apache.flink.types.Row
object WordCountByScalaSQL {
def main(args: Array[String]): Unit = {
val settings = EnvironmentSettings.newInstance.useBlinkPlanner.inStreamingMode.build
val env = StreamExecutionEnvironment.getExecutionEnvironment
// 创建SQL运行环境
val tableEnv = StreamTableEnvironment.create(env, settings);
// 接入数据源 Source
val text = env.fromElements(("zhangsan", 1), ("lisi", 2), ("zhangsan", 3))
// 将数据源映射为 Table
tableEnv.createTemporaryView("tmp_001", text.toTable(tableEnv, $("a"), $("b")))
// 执行查询语句,并用两种方式进行输出
val result = tableEnv.sqlQuery("SELECT a,count(1) v1,sum(b) v2 FROM tmp_001 group by a")
tableEnv.toRetractStream[(String, Long, Integer)](result).print().setParallelism(2)
tableEnv.toRetractStream[Row](result).print().setParallelism(2)
env.execute()
}
}
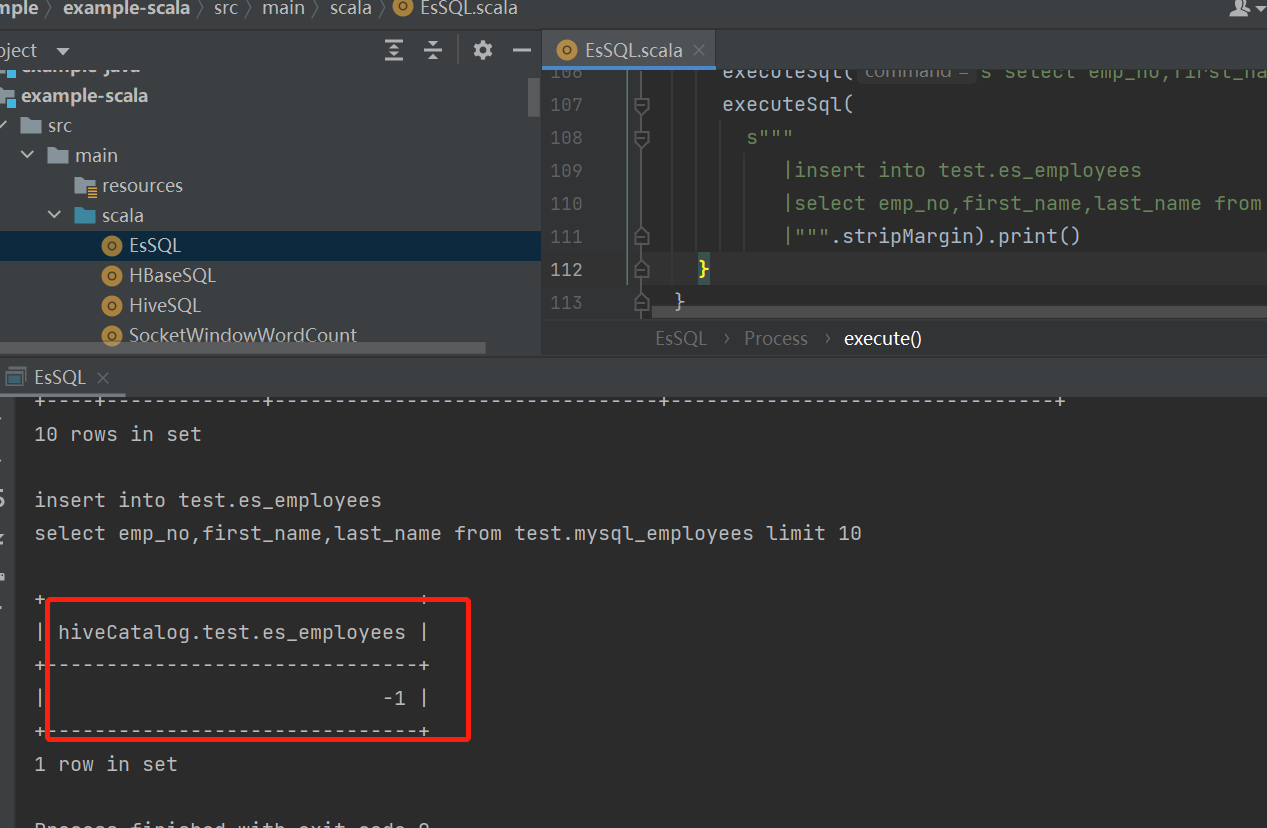
运行结果
本次代码接入的数据源是一个有界流,所以运行完直接结束
无界数据流
代码
import org.apache.flink.api.java.utils.ParameterTool
import org.apache.flink.api.scala._
import org.apache.flink.streaming.api.scala.StreamExecutionEnvironment
import org.apache.flink.table.api.bridge.scala.{StreamTableEnvironment, _}
import org.apache.flink.table.api.{EnvironmentSettings, _}
import org.apache.flink.types.Row
import scala.collection.mutable.Map
object WordCountByScalaSQL {
def main(args: Array[String]): Unit = {
val (host, port) = {
val pt = ParameterTool.fromArgs(args)
(pt.get("host"), pt.getInt("port"))
}
println("Connect to " + host + ":" + port);
val settings = EnvironmentSettings.newInstance.useBlinkPlanner.inStreamingMode.build
val env = StreamExecutionEnvironment.getExecutionEnvironment
// 创建SQL运行环境
val tableEnv = StreamTableEnvironment.create(env, settings);
// 接入数据源 Source
val text = env.socketTextStream(host, port, '\n').flatMap { w =>
val map = Map.empty[String, Int]
w.split("\\s+").map(_.trim).foreach(k => map += k -> (1 + map.getOrElse(k, 0)))
map
}
// 将数据源映射为 Table,数据源支持append模式
// 'a = $("a") = org.apache.flink.table.api.$("a") = Expressions.$("a")
val source = text.toTable(tableEnv, $("a"), $("b"))
tableEnv.createTemporaryView("tmp_001", source)
tableEnv.toAppendStream[Row](source).print().setParallelism(2)
// 执行查询语句,并用两种方式进行输出,查询由于用到了group by,不支持append模式
val result = tableEnv.sqlQuery("SELECT a,count(1) v1,sum(b) v2 FROM tmp_001 group by a")
tableEnv.toRetractStream[Row](result).print().setParallelism(2)
env.execute()
}
}
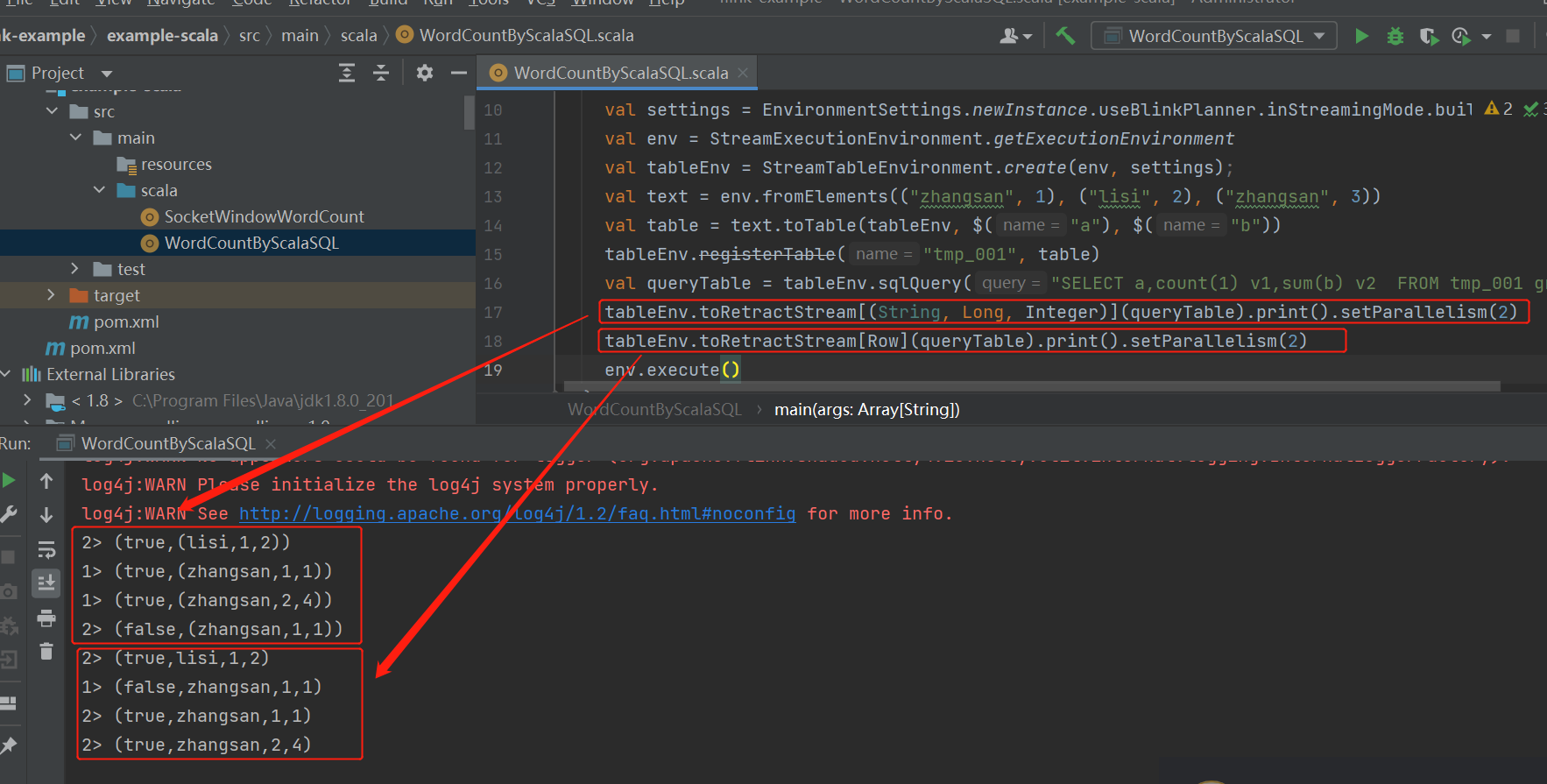
运行
[root@xx.xx.xx.xx ~]$ nc -l 9999
a ba a
a a a
hive
依赖
需要设置 HADOOP_HOME 环境变量,windows需要安装winutils.exe。
代码
import org.apache.flink.streaming.api.scala.StreamExecutionEnvironment
import org.apache.flink.table.api.EnvironmentSettings
import org.apache.flink.table.api.bridge.scala.StreamTableEnvironment
import org.apache.flink.table.catalog.hive.HiveCatalog
import java.io.File
import scala.collection.JavaConverters._
object HiveSQL {
val userDir = System.getProperty("user.dir")
val hiveConfDir = new File(userDir, "example-scala/src/main/resources/conf")
def main(args: Array[String]): Unit = {
val settings = EnvironmentSettings.newInstance.useBlinkPlanner.inStreamingMode.build
val env = StreamExecutionEnvironment.getExecutionEnvironment
val tableEnv = StreamTableEnvironment.create(env, settings);
val catalog = "hiveCatalog"
val hive = new HiveCatalog(catalog, "rtdw_default", hiveConfDir.getAbsolutePath, null)
tableEnv.registerCatalog(catalog, hive)
tableEnv.useCatalog(catalog)
tableEnv.getConfig.getConfiguration.setBoolean("table.dynamic-table-options.enabled", true)
val databaseList = hive.listDatabases().asScala
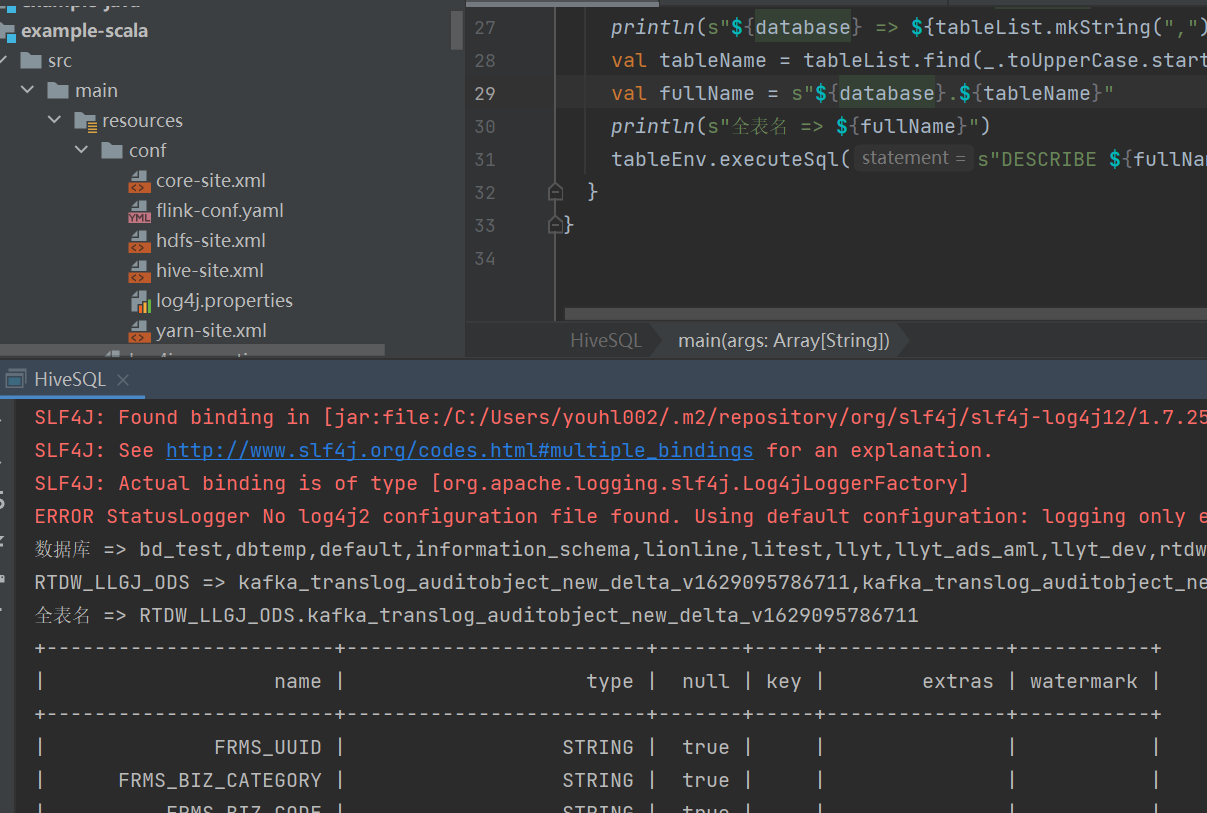
println(s"数据库 => ${databaseList.mkString(",")}")
val database = "RTDW_LLGJ_ODS"
val tableList = hive.listTables(database).asScala
println(s"${database} => ${tableList.mkString(",")}")
val tableName = tableList.find(_.toUpperCase.startsWith("KAFKA_TRANSLOG_AUDITOBJECT_NEW_DELTA")).get
val fullName = s"${database}.${tableName}"
println(s"全表名 => ${fullName}")
tableEnv.executeSql(s"DESCRIBE ${fullName}").print()
}
}
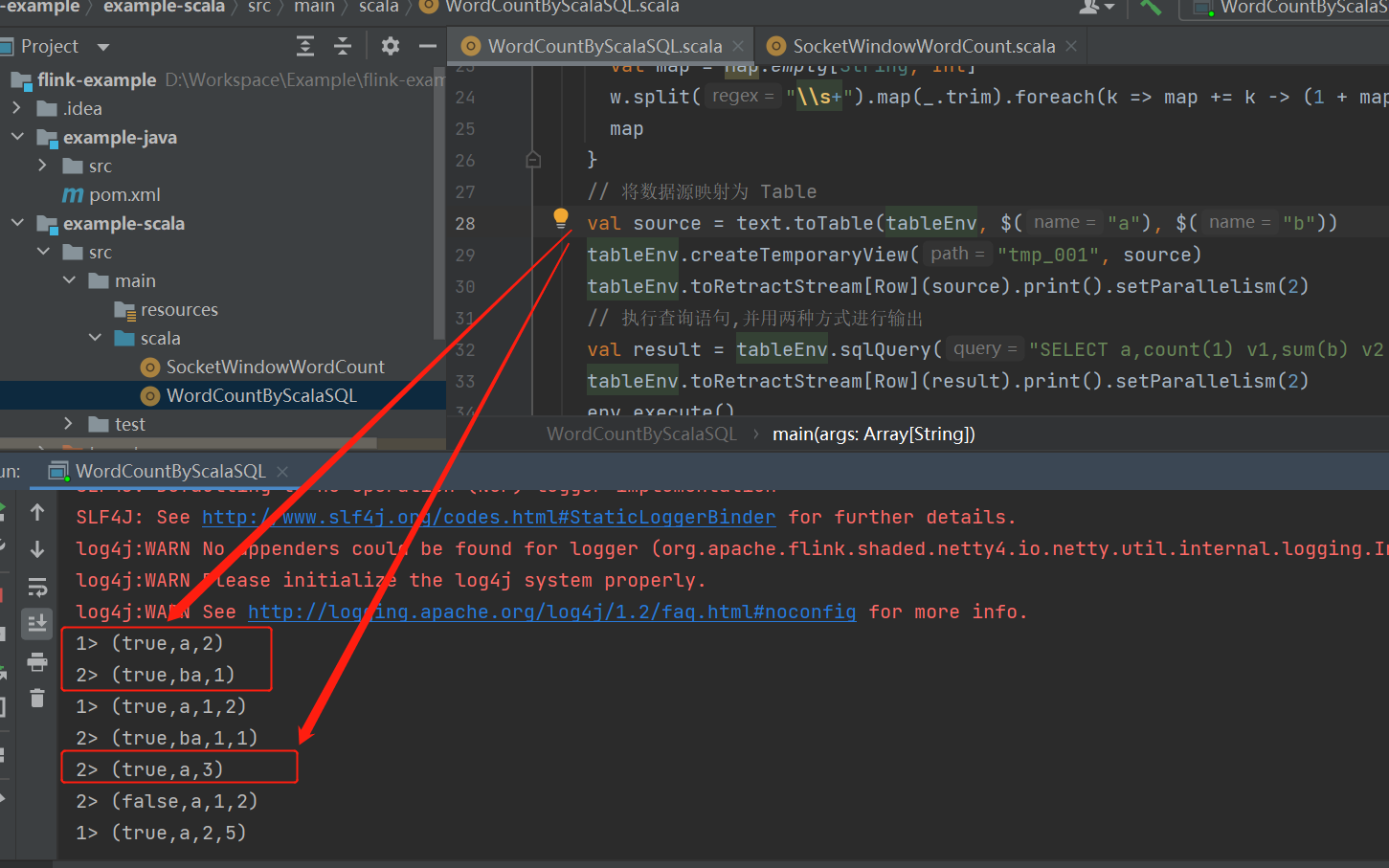
运行
RTDW_LLGJ_ODS.KAFKA_TRANSLOG_AUDITOBJECT_NEW_DELTA_v1634175536846 建表语句:
CREATE TABLE `RTDW_LLGJ_ODS`.`KAFKA_TRANSLOG_AUDITOBJECT_NEW_DELTA_v1634175536846` (
`FRMS_UUID` STRING COMMENT '',
`FRMS_BIZ_CATEGORY` STRING COMMENT '',
`FRMS_BIZ_CODE` STRING COMMENT '',
`FRMS_EMAIL` STRING COMMENT '',
`FRMS_IP_ADDR` STRING COMMENT '',
`FRMS_IP_ADDR_CITY` STRING COMMENT '',
`FRMS_IP_ADDR_COUNTRY` STRING COMMENT '',
`FRMS_IP_ADDR_DISTRICT` STRING COMMENT '',
`FRMS_IP_ADDR_PROVINCE` STRING COMMENT '',
`FRMS_PHONE_NO` STRING COMMENT '',
`FRMS_PHONE_NO_CARRIER` STRING COMMENT '',
`FRMS_PHONE_NO_CITY` STRING COMMENT '',
`FRMS_PHONE_NO_COUNTRY` STRING COMMENT '',
`FRMS_PHONE_NO_PROVINCE` STRING COMMENT '',
`FRMS_USER_ID` STRING COMMENT '',
`FRMS_USER_LOGIN` STRING COMMENT '',
`ORIG_VERIFY_FLAG` STRING COMMENT '',
`ODS_ROOT_TIME` STRING COMMENT '',
`BDRIVERKEY` STRING COMMENT 'BDRIVERKEY',
`BDRIVEROPTYPE` STRING COMMENT 'BDRIVEROPTYPE',
`BDRIVERTABLE` STRING COMMENT 'BDRIVERTABLE',
`PROCTIME` AS `PROCTIME`()
) WITH (
'connector' = 'kafka',
'topic' = 'ODS_TRANSLOG_AUDITOBJECT_NEW',
'properties.group.id' = 'irland_ewallet_dev',
'scan.startup.mode' = 'group-offsets',
'format' = 'json',
'properties.bootstrap.servers' = '192.168.134.64:9092'
);
对应底层的hive结构:
select tp.* from table_params tp
join tbls t on tp.TBL_ID = t.TBL_ID
where t.TBL_NAME = 'kafka_translog_auditobject_new_delta_v1629095786711';
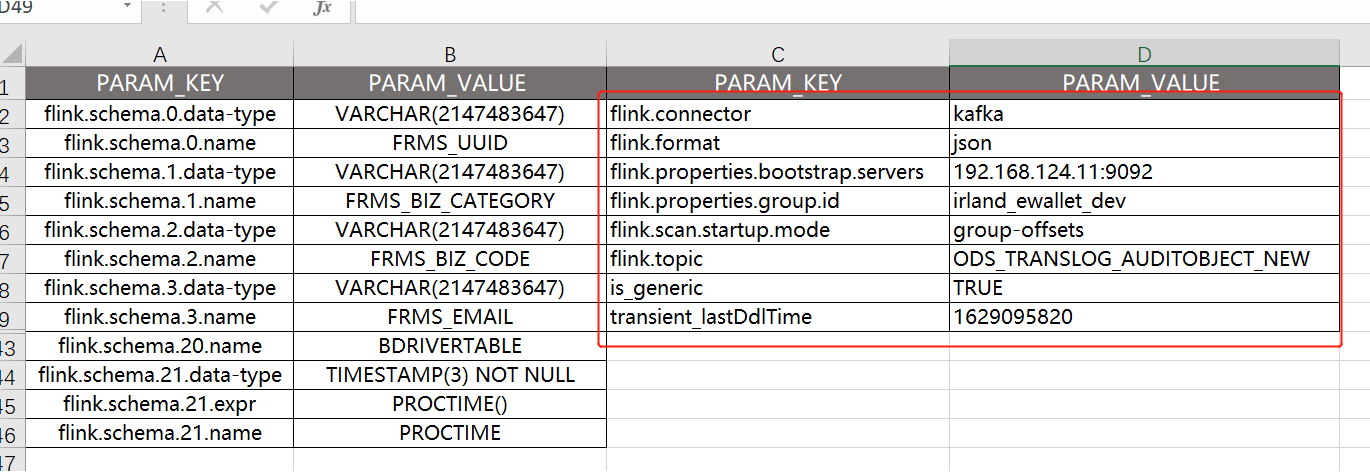
flink通过HiveCatalog创建的表底层存储在hive元数据中,该表结构只能在flink中使用,在hive中无法访问:
hbase
插入数据
import org.apache.flink.api.scala._
import org.apache.flink.streaming.api.scala.StreamExecutionEnvironment
import org.apache.flink.table.api.bridge.scala.{StreamTableEnvironment, _}
import org.apache.flink.table.api.{EnvironmentSettings, _}
import org.apache.flink.table.catalog.hive.HiveCatalog
import java.io.File
import scala.collection.JavaConverters._
import scala.collection.mutable.ArrayBuffer
object HBaseSQL {
val userDir = System.getProperty("user.dir")
val hiveConfDir = new File(userDir, "example-scala/src/main/resources/conf")
val hbaseQuorum = "xx:2181,yy:2181,zz:2181"
class HBaseSQL {
val settings = EnvironmentSettings.newInstance.useBlinkPlanner.inStreamingMode.build
val env = StreamExecutionEnvironment.getExecutionEnvironment
val tableEnv = StreamTableEnvironment.create(env, settings);
val catalog = "hiveCatalog"
val hive = new HiveCatalog(catalog, "rtdw_default", hiveConfDir.getAbsolutePath, null)
tableEnv.registerCatalog(catalog, hive)
tableEnv.useCatalog(catalog)
tableEnv.getConfig.getConfiguration.setBoolean("table.dynamic-table-options.enabled", true)
def getOrCreateTable(): String = {
val table = "RTDW_LLGJ_ODS.HBASE_TEST_01"
val database = table.split("\\.").head
var name = table.split("\\.").last.toLowerCase
val find = hive.listTables(database).asScala.find(_.toLowerCase.startsWith(name))
if (find.isDefined) return database + "." + find.get
name = s"${name}_v${System.currentTimeMillis()}"
// 需要预先创建hbase表: create 'RTDW_LLGJ_ODS:HBASE_TEST_01','f'
val ddl =
s"""
|CREATE TABLE ${database}.${name} (
| rowkey STRING,
| f ROW < uv BIGINT, click_count BIGINT >,
| PRIMARY KEY (rowkey) NOT ENFORCED
|) WITH (
|'connector' = 'hbase-1.4',
|'zookeeper.quorum' = '${hbaseQuorum}',
|'zookeeper.znode.parent' = '/hbase',
|'table-name' = 'RTDW_LLGJ_ODS:HBASE_TEST_01',
|'sink.buffer-flush.max-rows' = '1000'
|)
|""".stripMargin
tableEnv.executeSql(ddl).print()
database + "." + name
}
def execute(): Unit = {
val tableName = getOrCreateTable()
tableEnv.executeSql(s"DESCRIBE ${tableName}").print()
val stmt = tableEnv.createStatementSet()
stmt.addInsertSql(
s"""
|insert into ${tableName}
|SELECT 'baidu.com' rowkey, ROW(1,1) as f
|""".stripMargin)
stmt.execute().print()
tableEnv.executeSql(s"select h.rowkey host,h.f.uv uv,h.f.click_count cc from ${tableName} h").print()
}
}
def main(args: Array[String]): Unit = {
val sql = new HBaseSQL()
sql.execute()
}
}
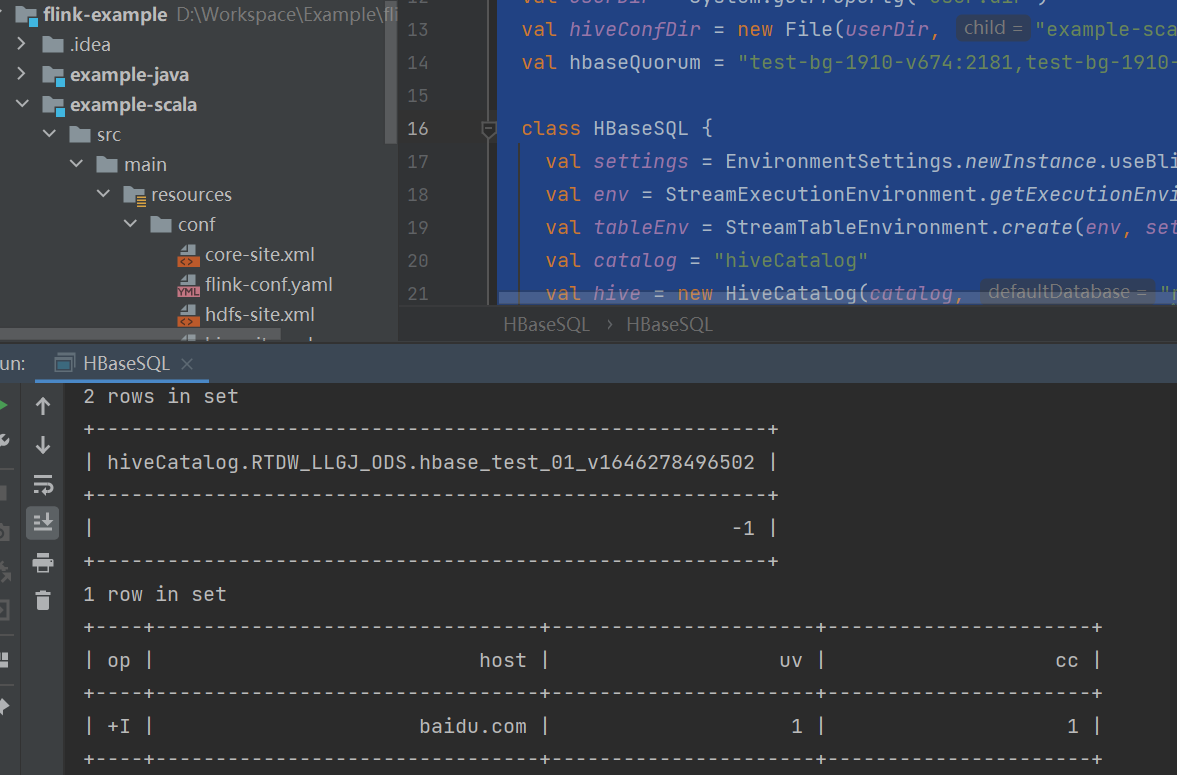
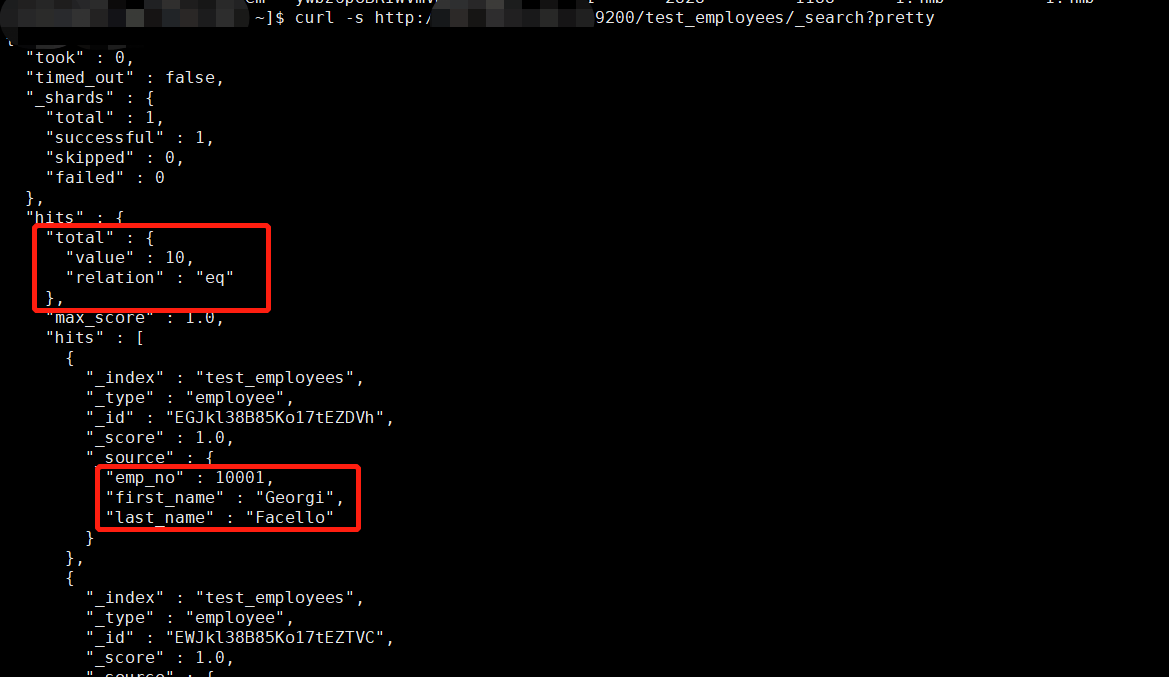
对应底层HBase数据:

统计插入
val buffer = ArrayBuffer.empty[(String, String, String)]
buffer.append(("baidu.com", "zhangsan", "click"))
buffer.append(("baidu.com", "zhangsan", "click"))
buffer.append(("sina.com", "zhangsan", "click"))
buffer.append(("qq.com", "zhangsan", "click"))
val source = env.fromCollection(buffer).toTable(tableEnv, $("name"), $("user"), $("action"))
tableEnv.createTemporaryView("tmp_001", source)
stmt.addInsertSql(
s"""
|insert into ${tableName}
|select name,row(count(distinct user),count(1)) f
|from tmp_001
|where action = 'click'
|group by name
|""".stripMargin)
stmt.execute().print()
tableEnv.executeSql(s"select h.rowkey host,h.f.uv uv,h.f.click_count cc from ${tableName} h").print()
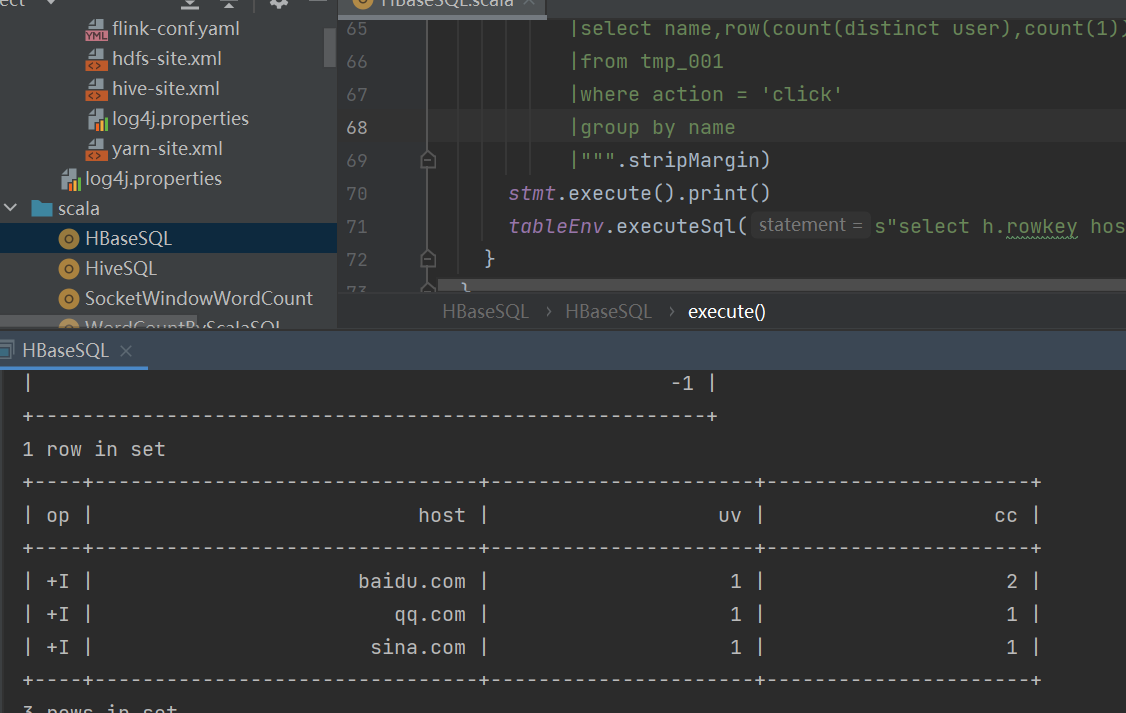
对应底层HBase数据:

elasticsearch
只能写(sink),不能读(source)
依赖
<properties>
<flink.version>1.12.3</flink.version>
</properties>
<dependencies>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-java</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-json</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-scala_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-planner-blink_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-hive_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-sql-connector-elasticsearch6_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-jdbc_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.49</version>
</dependency>
</dependencies>
代码
import org.apache.flink.streaming.api.scala.StreamExecutionEnvironment
import org.apache.flink.table.api.bridge.scala.StreamTableEnvironment
import org.apache.flink.table.api.{EnvironmentSettings, TableResult}
import org.apache.flink.table.catalog.hive.HiveCatalog
import java.io.File
import java.util.regex.Pattern
import scala.collection.JavaConverters._
object EsSQL {
val userDir = System.getProperty("user.dir")
val hiveConfDir = new File(userDir, "conf")
val esHost = "xx.xx.xx.xx"
val esPort = "9200"
val mysqlUrl = "jdbc:mysql://yy.yy.yy.yy:3306/employees?autoReconnect=true&connectTimeout=60000&socketTimeout=60000"
val mysqlUser = "root"
val mysqlPass = "mysql"
class Process {
val settings = EnvironmentSettings.newInstance.useBlinkPlanner.inStreamingMode.build
val env = StreamExecutionEnvironment.getExecutionEnvironment
val tableEnv = StreamTableEnvironment.create(env, settings);
val catalog = "hiveCatalog"
val hive = new HiveCatalog(catalog, "default", hiveConfDir.getAbsolutePath, null)
tableEnv.registerCatalog(catalog, hive)
tableEnv.useCatalog(catalog)
tableEnv.getConfig.getConfiguration.setBoolean("table.dynamic-table-options.enabled", true)
val stmt = tableEnv.createStatementSet()
def checkAndCreateTable(query: String, dropIfExists: Boolean = true): Unit = {
val pattern = Pattern.compile("\\s*create\\s+table\\s+([^\\s]+)\\s*", Pattern.CASE_INSENSITIVE | Pattern.MULTILINE)
val matcher = pattern.matcher(query)
if (!matcher.find()) throw new IllegalArgumentException("建表语句异常 => " + query)
val fullName = matcher.group(1)
val ss = fullName.split("\\.")
val database = if (ss.length > 1) ss(0) else ""
val tableName = if (ss.length > 1) ss.slice(1, ss.length).mkString(".") else ss(0)
if (!database.isEmpty) {
if (!database.equalsIgnoreCase(HiveCatalog.DEFAULT_DB) && !hive.databaseExists(database)) {
executeSql(s"create database ${database}").print()
}
}
if (hive.listTables(database).asScala.find(_.equalsIgnoreCase(tableName)).isDefined) {
if (!dropIfExists) {
println(s"${fullName} has been created.")
return
}
executeSql(s"drop table if exists ${fullName}").print()
}
executeSql(query).print()
}
def initTable(): Unit = {
checkAndCreateTable(
s"""
|CREATE TABLE test.mysql_employees (
|emp_no INT NOT NULL,
|birth_date date,
|first_name varchar(14),
|last_name varchar(16),
|gender varchar(1),
|hire_date date
|) WITH (
| 'connector' = 'jdbc',
| 'driver' = 'com.mysql.jdbc.Driver',
| 'url' = '${mysqlUrl}',
| 'username' = '${mysqlUser}',
| 'password' = '${mysqlPass}',
| 'table-name' = 'employees'
|)
|""".stripMargin, false)
checkAndCreateTable(
s"""
|CREATE TABLE test.es_employees (
| emp_no INT NOT NULL,
| first_name varchar(14),
| last_name varchar(16),
| PRIMARY KEY (emp_no) NOT ENFORCED
|) WITH (
| 'connector.type' = 'elasticsearch',
| 'connector.version' = '6',
| 'connector.hosts' = 'http://${esHost}:${esPort}',
| 'connector.index' = 'test_employees',
| 'connector.document-type' = 'employee',
| 'connector.bulk-flush.max-actions' = '1', -- 每条数据都刷新
| 'format.type' = 'json',
| 'update-mode' = 'upsert'
|)
|""".stripMargin)
}
def executeSql(command: String): TableResult = {
println(command)
tableEnv.executeSql(command)
}
def execute(): Unit = {
initTable()
executeSql(s"select emp_no,first_name,last_name from test.mysql_employees limit 10").print()
executeSql(
s"""
|insert into test.es_employees
|select emp_no,first_name,last_name from test.mysql_employees limit 10
|""".stripMargin).print()
}
}
def main(args: Array[String]): Unit = {
val process = new Process();
process.execute()
}
}
运行