
Environment
getExecutionEnvironment
创建一个执行环境,表示当前执行程序的上下文。如果程序是独立调用的,则此方法返回本地执行环节;如果从命令行客户端调用程序以提交到集群,则此方法返回刺激群的执行环境,也就是说,
getExecutionEnvironment会根据查询运行的方式决定返回什么样的运行环境,是最常用的一种创建执行环境的方式。
// 批处理执行环境
ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
// 流式执行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment .getExecutionEnvironment();
如果没有设置并行度,会以
flink-conf.yaml中配置parallelism.default为准,默认为1。
createLocalEnvironment
返回本地执行环境,需要在调用时指定默认的并行度。
LocalStreamEnvironment env = StreamExecutionEnvironment .getLocalEnvironment(1);
createRemoteEnvironment
返回集群执行环境,将jar包提交到远程服务器。需要在调用时指定
JobManager的ip和端口,并指定要在集群中运行的jar包。
StreamExecutionEnvironment env = StreamExecutionEnvironment .createRemoteEnvironment("jobmanager",6123,"hdfs://${nsName}/flink/lib/WordCount.jar");
Source
集合
import java.util.Arrays;
import lombok.AllArgsConstructor;
import lombok.Data;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
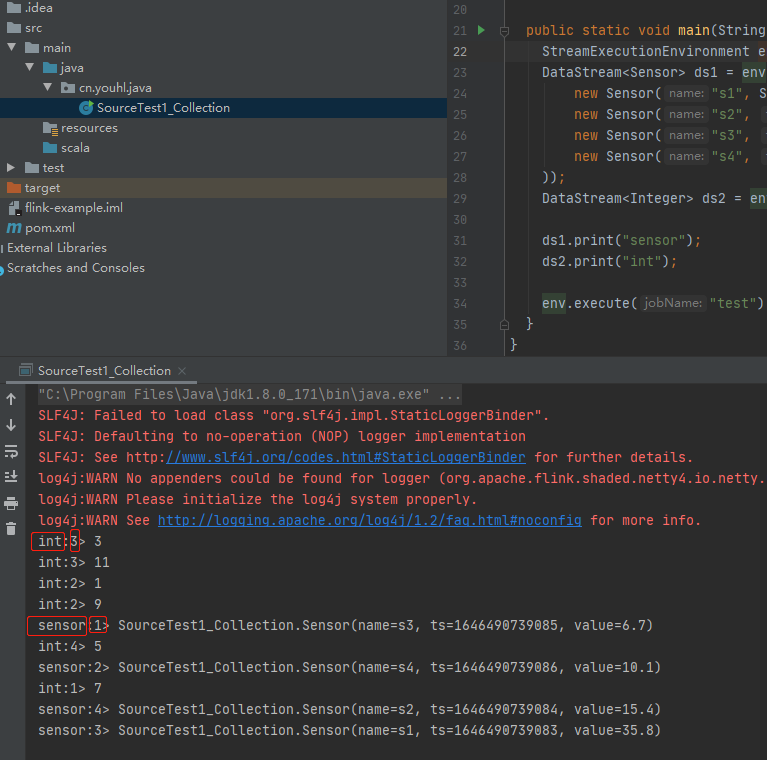
public class SourceTest1_Collection {
@Data
@AllArgsConstructor
private static class Sensor {
private String name;
private Long ts;
private Double value;
}
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// env.setParallelism(1); // 并行度设置为1,输出不会有分区号且严格顺序执行
DataStream<Sensor> ds1 = env.fromCollection(Arrays.asList(
new Sensor("s1", System.currentTimeMillis(), 35.8),
new Sensor("s2", System.currentTimeMillis() + 1, 15.4),
new Sensor("s3", System.currentTimeMillis() + 2, 6.7),
new Sensor("s4", System.currentTimeMillis() + 3, 10.1)
));
DataStream<Integer> ds2 = env.fromElements(1, 3, 5, 7, 9, 11);
ds1.print("sensor");
ds2.print("int");
env.execute("test");
}
}
import org.apache.flink.streaming.api.scala._
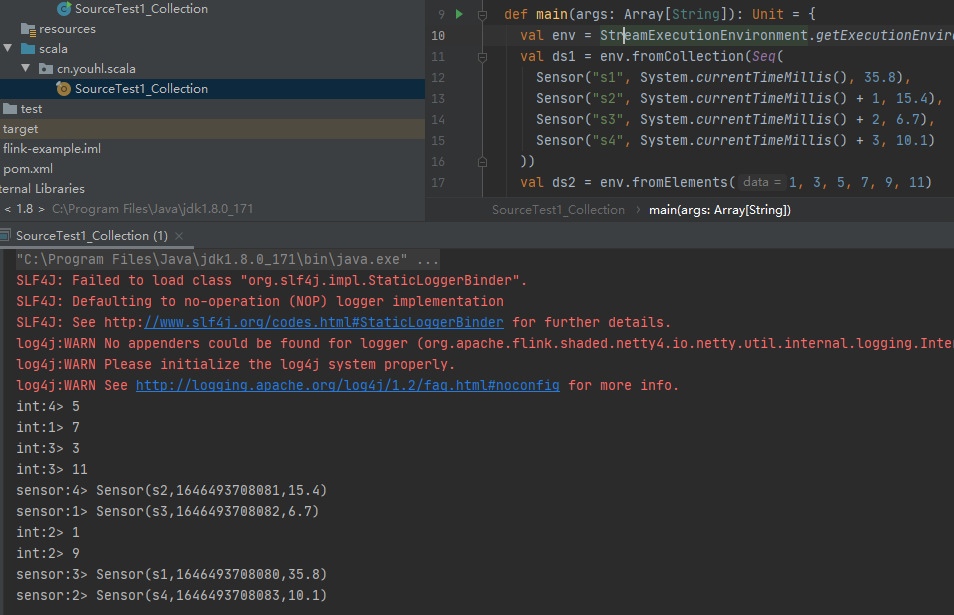
object SourceTest1_Collection {
case class Sensor(name: String, ts: Long, value: Double)
def main(args: Array[String]): Unit = {
val env = StreamExecutionEnvironment.getExecutionEnvironment
val ds1 = env.fromCollection(Seq(
Sensor("s1", System.currentTimeMillis(), 35.8),
Sensor("s2", System.currentTimeMillis() + 1, 15.4),
Sensor("s3", System.currentTimeMillis() + 2, 6.7),
Sensor("s4", System.currentTimeMillis() + 3, 10.1)
))
val ds2 = env.fromElements(1, 3, 5, 7, 9, 11)
ds1.print("sensor")
ds2.print("int")
env.execute("test")
}
}
文件
import java.net.URL;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
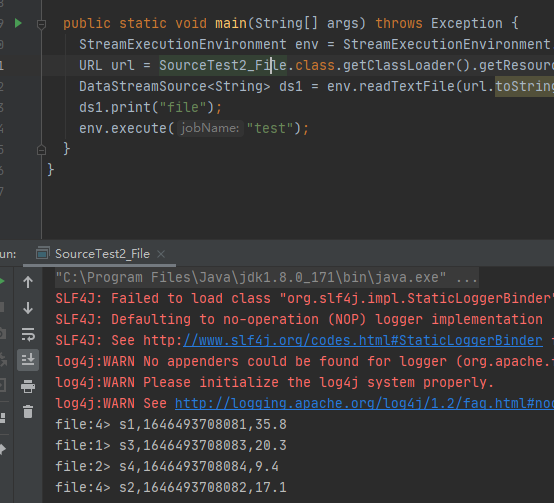
public class SourceTest2_File {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
URL url = SourceTest2_File.class.getClassLoader().getResource("sensor.csv");
DataStreamSource<String> ds1 = env.readTextFile(url.toString());
ds1.print("file");
env.execute("test");
}
}
socket
import org.apache.flink.api.java.utils.ParameterTool;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
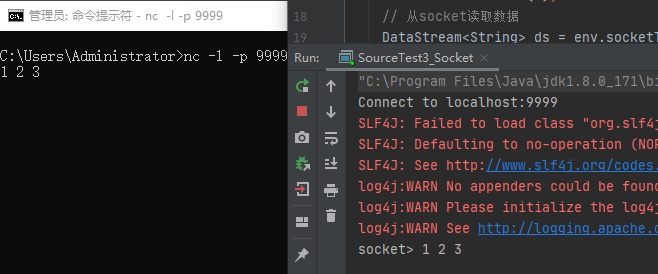
public class SourceTest3_Socket {
public static void main(String[] args) throws Exception {
// 1. nc -l -p 9999
// 2. 获取命令传递参数 --host localhost --port 9999
ParameterTool params = ParameterTool.fromArgs(args);
String host = params.get("host", "localhost");
int port = params.getInt("port", 9999);
System.out.println("Connect to " + host + ":" + port);
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
// 从socket读取数据
DataStream<String> ds = env.socketTextStream(host, port, "\n");
ds.print("socket");
env.execute("test");
}
}
kafka
连接器依赖:
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-kafka-0.11_2.11</artifactId>
<version>1.11.3</version>
</dependency>
import java.util.Properties;
import org.apache.flink.api.common.serialization.SimpleStringSchema;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer011;
import org.apache.kafka.common.serialization.StringDeserializer;
public class SourceTest3_Kafka {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
// kafka配置
Properties properties = new Properties();
properties.setProperty("bootstrap.servers", "localhost:9092");
properties.setProperty("group.id", "consumer-group");
properties.setProperty("key.deserializer", StringDeserializer.class.getName());
properties.setProperty("value.deserializer", StringDeserializer.class.getName());
properties.setProperty("auto.offset.reset", "latest");
// 从kafka读取数据
DataStream<String> ds = env.addSource(new FlinkKafkaConsumer011<>("sensor", new SimpleStringSchema(), properties));
ds.print();
env.execute("test");
}
}
自定义
除了以上的source数据来源,还可以自定义source。需要做的,就是实现SourceFunction接口就可以了。具体调用如下:
SourceFunction的实现类的内部变量会被序列化后传递到TaskManager执行,所以在client中对原来的SourceFunction内部变量做修改操作是无效的。
import java.util.LinkedList;
import java.util.Queue;
import java.util.UUID;
import java.util.concurrent.ThreadLocalRandom;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.source.SourceFunction;
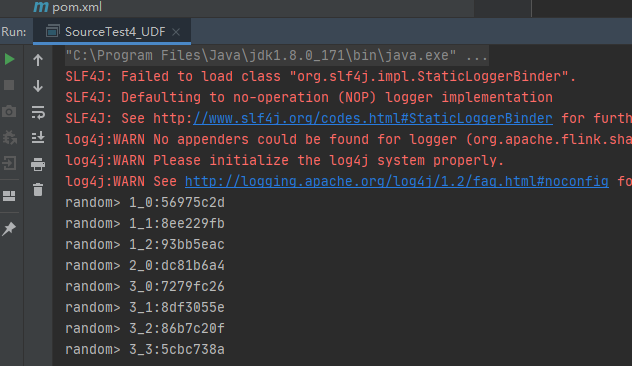
public class SourceTest4_UDF {
// 自定义的SourceFunction
private static class MySourceFunction implements SourceFunction<String> {
private volatile boolean running = true;
@Override
public void run(SourceContext<String> ctx) throws InterruptedException {
Queue<String> queue = new LinkedList<>();
int batch = 0;
while (running) {
// 生成数据
batch++;
int size = ThreadLocalRandom.current().nextInt(4) + 1;
for (int i = 0; i < size; i++) {
String key = batch + "_" + i;
String message = UUID.randomUUID().toString().split("-")[0];
queue.add(key + ":" + message);
}
// 搜集数据
while (!queue.isEmpty()) {
ctx.collect(queue.poll());
}
Thread.sleep(1000 * 3);
}
}
@Override
public void cancel() {
running = false;
}
}
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
// 从kafka读取数据
MySourceFunction source = new MySourceFunction();
DataStream<String> ds = env.addSource(source);
ds.print("random");
env.execute("test");
}
}
Transform
转换算子
map
DataStream<Double> ds3 = env.fromElements("1", "2")
.map((MapFunction<String, Double>) value -> Double.parseDouble(value));
flatMap
DataStream<String> ds4 = env.fromElements("hello", "world").flatMap(
(FlatMapFunction<String, String>) (value, out) -> Arrays.stream(value.split("\\s+"))
.forEach(e -> out.collect(e)));
filter
DataStream<String> ds5 = env.fromElements("hello world").filter(
(FilterFunction<String>) value -> value.equals("hello"));
keyBy
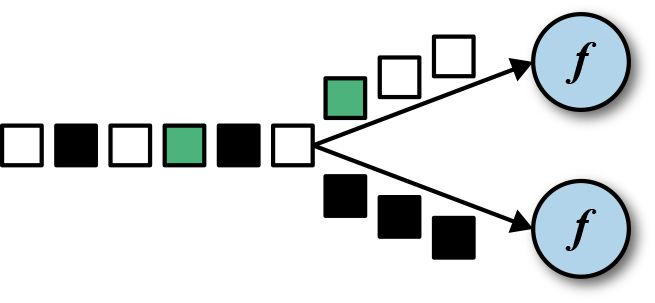
DataStream -> KeyedStream: 逻辑地江一个流拆分成不想交的分区,每个分区包含具有相同key的元素,在内部以hash的形式实现。
Rolling Aggregation(滚动聚合算子)
这些算子可以针对KeyedStream的每一个支流做聚合。
- sum
- min
- max
- minBy
- maxBy
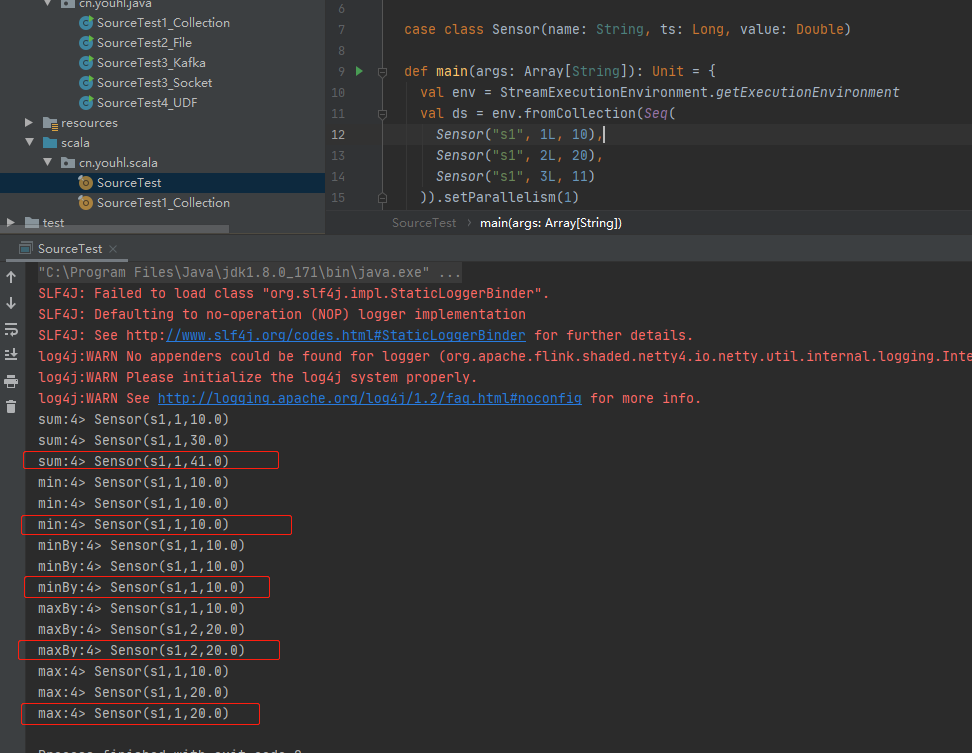
case class Sensor(name: String, ts: Long, value: Double)
val ds = env.fromCollection(Seq(
Sensor("s1", 1L, 10),
Sensor("s1", 2L, 20),
Sensor("s1", 3L, 11)
)).setParallelism(1)
ds.keyBy(_.name).sum("value").print("sum")
ds.keyBy(_.name).min("value").print("min")
ds.keyBy(_.name).max("value").print("max")
ds.keyBy(_.name).minBy("value").print("minBy")
ds.keyBy(_.name).maxBy("value").print("maxBy")
reduce
KeyedStream -> DataStream: 一个分组数据流的聚合操作,合并当前的元素和上次聚合的结果,产生一个新的值,返回的流中包含每一次聚合的结果,而不是只返回最后一次聚合的最终结果。
// 注意数据对象必须是 POJO types, tuples, and case classes
class Sensor() {
def this(name: String, ts: Long, value: Double) {
this()
this.name = name
this.ts = ts
this.value = value
}
var name: String = _
var ts: Long = _
var value: Double = _
// 此处不能声明为 val
var map = Map.empty[String, Double]
}
val ds = env.fromCollection(Seq(
new Sensor("s1", 1L, 10),
new Sensor("s1", 2L, 20),
new Sensor("s1", 3L, 11)
)).setParallelism(1)
// 计算合计温度
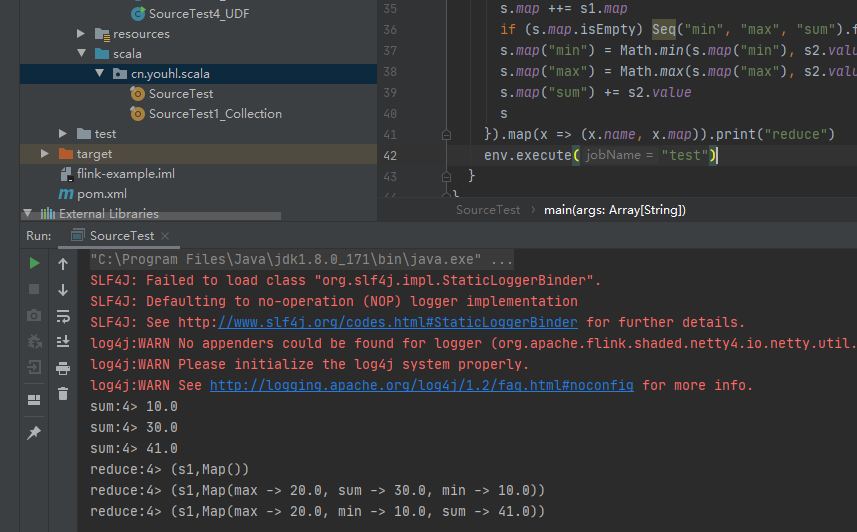
ds.keyBy(_.name).sum("value").map(_.value).print("sum")
// 同时计算 最小,最大,合计 问题
ds.keyBy(_.name).reduce((s1, s2) => {
val s = new Sensor(s1.name, s1.ts, s1.value)
s.map ++= s1.map
if (s.map.isEmpty) Seq("min", "max", "sum").foreach(k => s.map += k -> s.value)
s.map("min") = Math.min(s.map("min"), s2.value)
s.map("max") = Math.max(s.map("max"), s2.value)
s.map("sum") += s2.value
s
}).map(x => (x.name, x.map)).print("reduce")
split和select
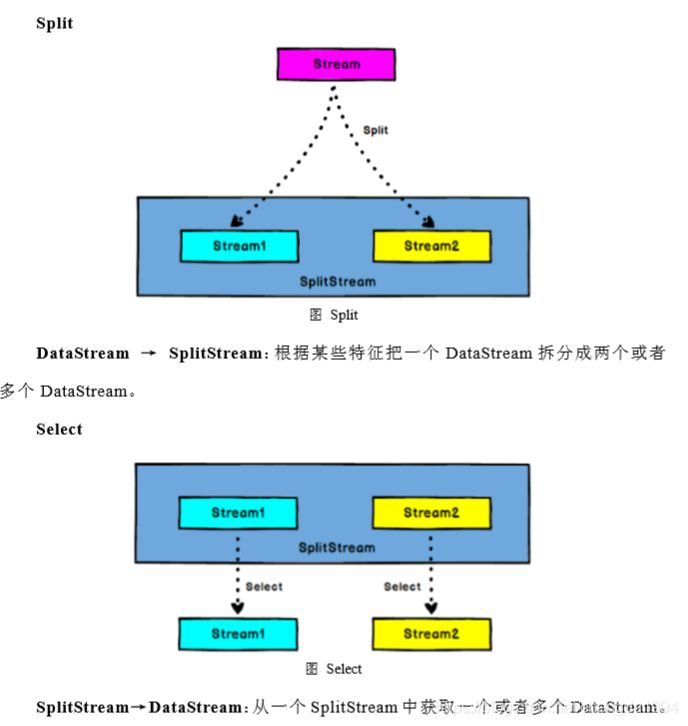
需求:传感器数据按照温度高低(30为界),拆分成低温和高温流
case class Sensor(name: String, ts: Long, value: Double)
def main(args: Array[String]): Unit = {
val env = StreamExecutionEnvironment.getExecutionEnvironment
val ds = env.fromCollection(Seq(
Sensor("s1", 1L, 10),
Sensor("s2", 2L, 35),
Sensor("s3", 3L, 25),
Sensor("s4", 4L, 40)
)).setParallelism(1)
val split = ds.split(s => Seq(if (s.value > 30) "high" else "low"))
split.select("high").print("high")
split.select("low").print("low")
split.select("high", "low").print("all")
env.execute("test")
}
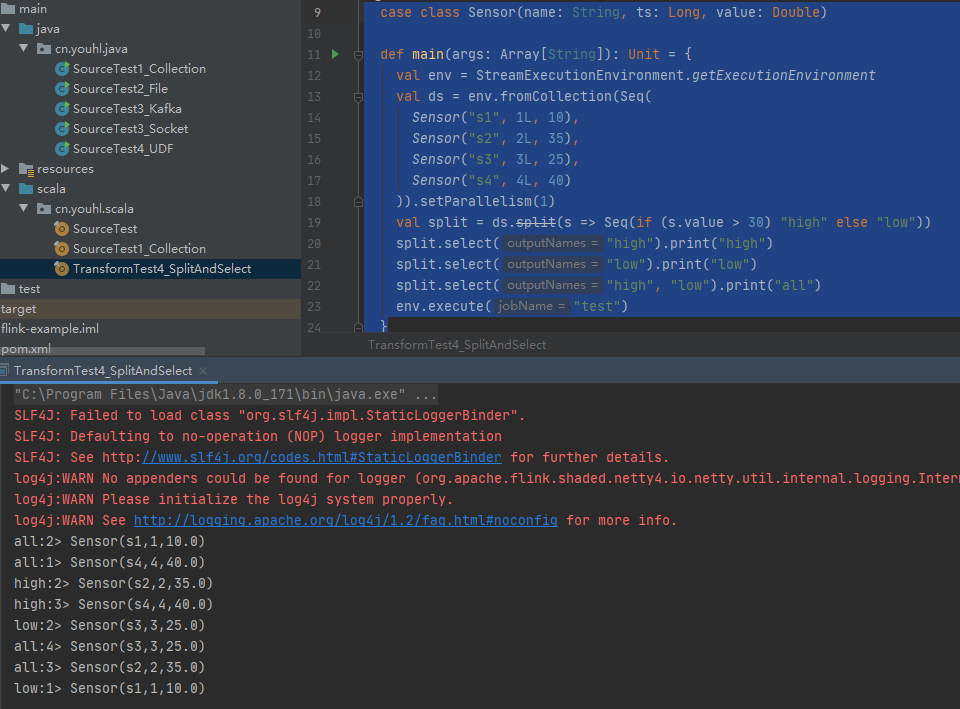
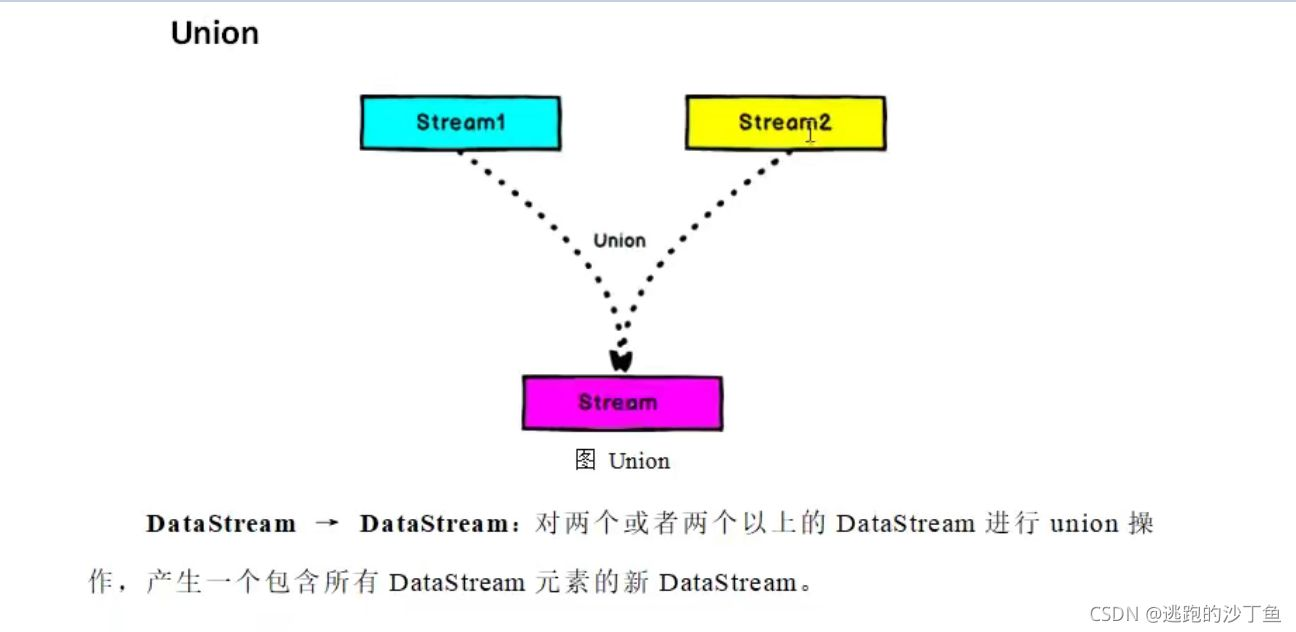
connect和coMap
DataStream,DataStream -> ConnectedStreams:连接两个保持他们类型的数据流,两个数据流被Connect之后,只是被放在了一个同一个流中,内部依然保持各自的数据和形式不发生任何变化,两个流相互独立。
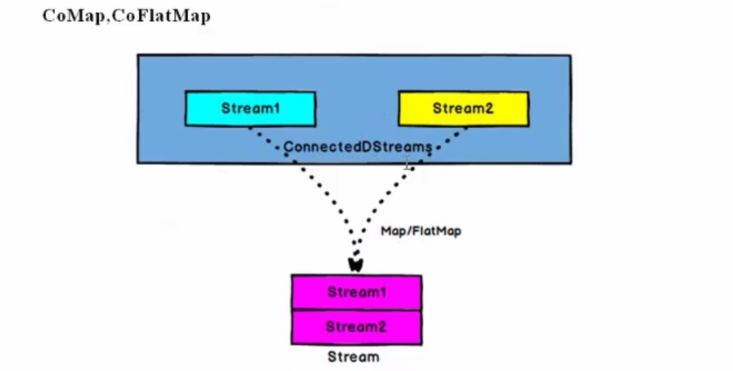
ConnectedStreams -> DataStream: 作用于ConnectedStreams上,功能与map和flatMap一样,对ConnectedStreams中的每一个Stream分别进行map和flatMap处理。
实现一个简单的join程序:
case class Student(id: Int, name: String)
case class Score(studentId: Int, subjectId: Int, score: Double)
case class Subject(id: Int, name: String)
class Group() {
def this(id: Int) {
this()
this.id = id
}
var id: Int = _
var map = Map.empty[String, Any]
def append[T](key: String, value: T): Group = {
this.map += key -> value
this
}
def append[T](map: Map[String, Any]): Group = {
this.map ++= map
this
}
def getAs[T](name: String): T = map(name).asInstanceOf[T]
override def toString: String = s"id=${id},map=${map}"
}
def main(args: Array[String]): Unit = {
val env = StreamExecutionEnvironment.getExecutionEnvironment
env.setParallelism(1)
val rd = new Random()
val studentDs = env.fromCollection("张三,李四".split(",").zipWithIndex.map(x => Student(x._2, x._1)))
val subjectDs = env.fromCollection("数学,语文,英语".split(",").zipWithIndex.map(x => Student(x._2, x._1)))
val scoreDs = env.fromCollection(Seq(
Score(0, 0, (rd.nextDouble() * 100).toInt),
Score(0, 1, (rd.nextDouble() * 100).toInt),
Score(0, 2, (rd.nextDouble() * 100).toInt),
Score(1, 0, (rd.nextDouble() * 100).toInt),
Score(1, 1, (rd.nextDouble() * 100).toInt),
Score(1, 2, (rd.nextDouble() * 100).toInt)
))
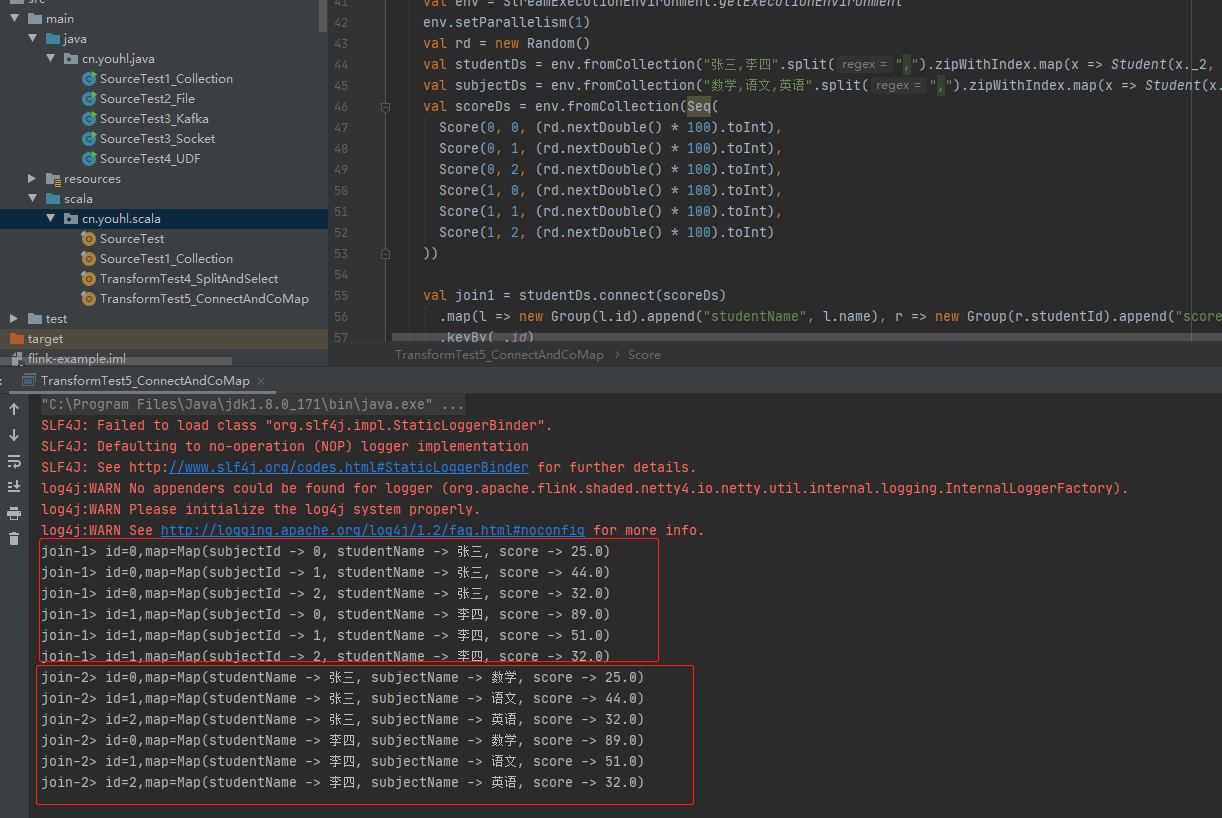
val join1 = studentDs.connect(scoreDs)
// coMap 将两个流的类型合并成同一个类型
.map(l => new Group(l.id).append("studentName", l.name), r => new Group(r.studentId).append("score", r.score).append("subjectId", r.subjectId))
.keyBy(_.id)
.reduce((g1, g2) => new Group(g1.id).append(g1.map).append(g2.map))
.filter(_.map.contains("score"))
join1.print("join-1")
val join2 = join1.connect(subjectDs)
.map(l => new Group(l.getAs("subjectId")).append(l.map.filter(_._1 != "subjectId")), r => new Group(r.id).append("subjectName", r.name))
.keyBy(_.id)
.reduce((g1, g2) => new Group(g1.id).append(g1.map).append(g2.map))
.filter(_.map.contains("score"))
join2.print("join-2")
env.execute("test")
}
union
支持的数据类型
Flink流应用程序处理的是以数据对象表示的事件流。所以在Flink内部,我们需要能够处理这些对象。它们需要被序列化和反序列化,以便通过网络传送它们;或者从状态后端、检查点和保存点读取它他们。为了有效地做到这一点,Flink需要明确知道应用程序所处理的数据类型。Flink使用类型信息的概念来表示数据类型,并为每个数据类型生成特定的序列化、反序列化器和比较器。
Flink还具有一个类型提取系统,该系统分析函数的输入和返回类型,以自动获取类型信息,从而获得序列化器和反序列化器。但是,在某些情况下,例如lambda函数和泛型类型,需要显式地提供类型信息,才能使应用程序正常工作或提交其性能。
Flink支持Java和Scala中所有常见数据类型。使用最广泛的类型有以下几种。
基础数据类型
FLink支持所有Java和Scala基础数据类型,Int,Double,Long,String,...
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.fromElements(1, 2, 3, 4).print();
env.execute("test");
Java和Scala元组(Tuples)
DataStreamSource<Tuple2<Integer,String>> ds = env.fromElements(new Tuple2<>(1,"zhangsan"));
ds.filter(t -> t.f0 >= 1).print();
Scala样例类(Case Classes)
case class Student(id: Int, name: String)
env.fromElements(Student(1, "zhangsan")).print("test")
Java简单对象(POJOs)
@AllArgsConstructor
public static class Student{
private int id;
private String name;
}
env.fromElements(new Student(1, "zhangsan")).print();
其他(Arrays,Lists,Maps,Enums等等)
FLink对于Java和Scala中的一些特殊目的的类型也是支持的,比如Java的ArrayList,HashMap,Enum等类型
实现UDF函数-更细力度的控制流
函数类(Function Classes)
Flink暴露了所有udf函数的接口,例如MapFunction,FilterFunction,ProcessFunction等等
匿名函数(Lambda Functions)
富函数(Rich Functions)
“富函数”是DataStream API提供的一个函数类的接口,所有Flink函数类都有其Rich版本。它与常规函数的不同在于,可以获取运行环境的上下文,并拥有一些生命周期方法,所以可以实现更加复杂的功能。
- RichMapFunction
- RichFlatMapFunction
- RichFilterFunction
- ...
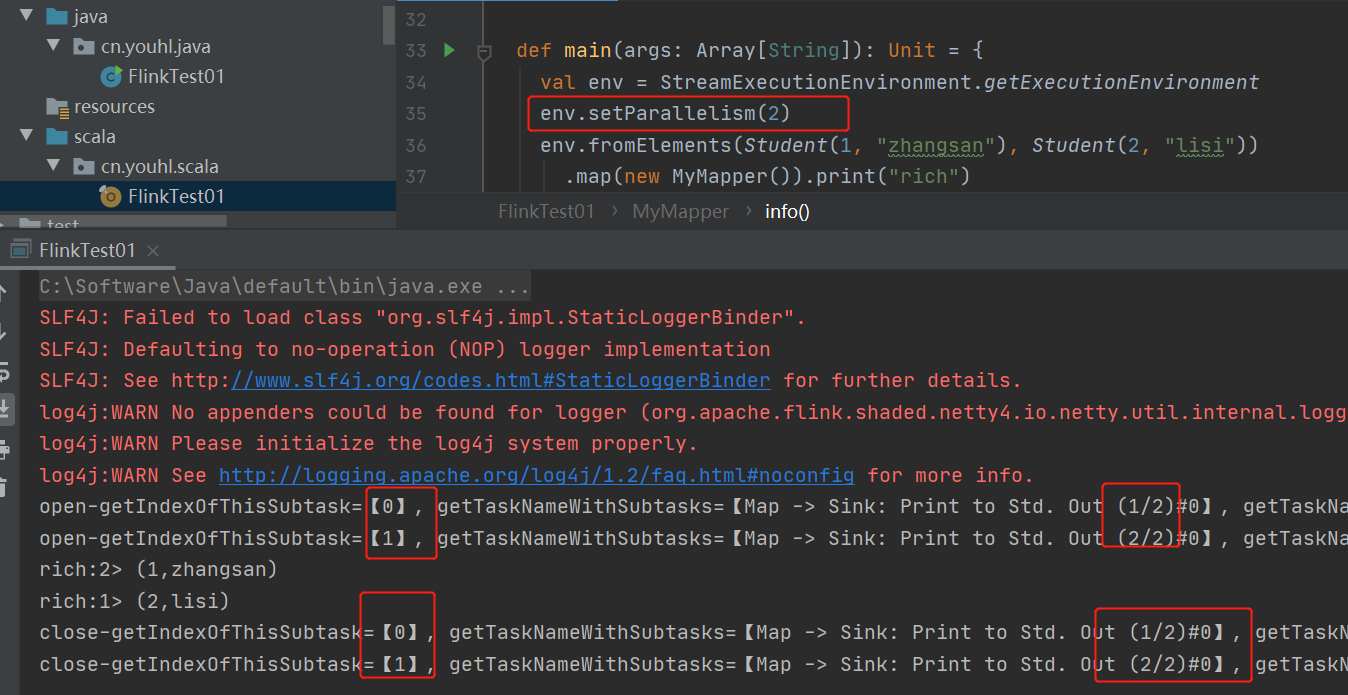
Rich Function有一个生命周期的概念。典型的生命周期方法有:
- open()方法是rich function的初始化方法,当一个算子例如map或者filter被调用之前open()会被调用。
- close()方法是声明周期中的最后一个调用的方法,做一些清理工作。
- getRuntimeContext()方法提供了函数的RuntimeContext的一些信息,例如函数执行的并行度,任务的名称,以及state状态
case class Student(id: Int, name: String)
class MyMapper extends RichMapFunction[Student, (Int, String)] {
override def open(parameters: Configuration): Unit = println(s"open-${info()}")
override def map(s: Student): (Int, String) = (s.id, s.name)
override def close(): Unit = println(s"close-${info()}")
private def info() = {
val ctx = getRuntimeContext()
val buffer = ArrayBuffer.empty[(String, Any)]
buffer += "getIndexOfThisSubtask" -> ctx.getIndexOfThisSubtask
buffer += "getTaskNameWithSubtasks" -> ctx.getTaskNameWithSubtasks
buffer += "getTaskName" -> ctx.getTaskName
buffer += "getNumberOfParallelSubtasks" -> ctx.getNumberOfParallelSubtasks
buffer += "getMaxNumberOfParallelSubtasks" -> ctx.getMaxNumberOfParallelSubtasks
buffer += "getAttemptNumber" -> ctx.getAttemptNumber
buffer.map(s => s"${s._1}=【${s._2}】").mkString(", ")
}
}
def main(args: Array[String]): Unit = {
val env = StreamExecutionEnvironment.getExecutionEnvironment
env.setParallelism(2)
env.fromElements(Student(1, "zhangsan"), Student(2, "lisi"))
.map(new MyMapper()).print("rich")
env.execute()
}
其他方法:
def main(args: Array[String]): Unit = {
val env = StreamExecutionEnvironment.getExecutionEnvironment
env.setParallelism(3)
val ds = env.fromCollection(0 until 10)
ds.print("source")
ds.rebalance.print("rebalance")
ds.shuffle.print("shuffle")
ds.global.print("global")
env.execute()
}
Sink
Flink没有类似spark中国foreach方法,让用户进行迭代的操作。所有对外的输出操作都要利用Sink完成。最后通过类似如下方式完成整个任务最终输出操作。
strem.addSink(new MySink(xxx))
官方提供了一部分框架的sink。除此之外,用户也可以自定义实现sink。
Bundled Connectors

Apache Bahir
kafka
val env = StreamExecutionEnvironment.getExecutionEnvironment
val brokers = "localhost:9092"
val (fromTopic, toTopic) = ("topic-1", "topic-2")
val properties = new Properties()
properties.setProperty("bootstrap.servers", brokers);
properties.setProperty("group.id", "consumer-group");
properties.setProperty("key.deserializer", classOf[StringDeserializer].getName);
properties.setProperty("value.deserializer", classOf[StringDeserializer].getName);
properties.setProperty("auto.offset.reset", "latest");
// 从kafka读取数据
val from = env.addSource(new FlinkKafkaConsumer011(fromTopic, new SimpleStringSchema(), properties));
// ETL process
val to = from.filter(_.length > 0)
// 推送到kafka
to.addSink(new FlinkKafkaProducer011(brokers, toTopic, new SimpleStringSchema()))
env.execute()